
The AI world loves climbing leaderboards. Companies race to hit #1 on LMSYS, chase perfect scores on academic benchmarks, and demo SVGs of pelicans on bicycles. These achievements make for great headlines and impressive presentations – even when these metrics are easily hacked.
What doesn't make headlines? A teacher spending 25 minutes trying to get ChatGPT to extract clean text from a PDF. An SMB owner frustrated that their favorite chatbot keeps hallucinating non-existent Excel files. The friction that happens when AI goes into the real world.
Real user problems are messy, contextual, and often surprisingly basic. These unsexy failures represent the gap between AI's promise and its reality – but how many researchers viscerally understand where models stumble in daily use?
We wanted to bridge this gap by asking 1,000 people to share real conversations where ChatGPT let them down, and verifying that other leading models (like Gemini and Claude) struggled with the same tasks. This series will dive deep into these everyday, unsexy failures, and the capabilities needed to solve them.
Let’s start with a task that feels almost insultingly simple: copying text out of a PDF and into a Word document.
Failure #1: Failing to extract text from a PDF
Meet Josephina
Meet Josephina, a teacher who relies heavily on ChatGPT, in her own words:
I use ChatGPT for pretty much everything these days. I’m a teacher, so I use it to help me plan and assess. I also use it to help me lead wider school initiatives and brainstorm ideas. In my personal life, I ask it about my baby and her development, as well as using it for general therapy. Recently, I’ve started using it to practice my rusty German skills and grammar. Also, I’ve recently started a small business and have found it particularly helpful for social media marketing strategies. I’m also a bit embarrassed to admit this but it might help the conversation make sense: I call “her” Cathy.
Her Seemingly Simple Goal
Josephina had a straightforward goal:
I had a document on writing frameworks, and I wanted to use it to create a booklet to help my teacher colleagues.
I wanted the text of one section, but without the footnotes or image captions - just the raw text. Specifically, I wanted ChatGPT to extract the text from section 4 without the footnotes, so that it would be easier to copy and paste whole sections.
The problem? After 25 minutes of hitting a wall with ChatGPT, she gave up and did it herself.
Here’s Josephina narrating the troubles she encountered.
What Went Wrong: A Step-by-Step Breakdown
Round 1: The Ambiguity Trap
First, I asked ChatGPT (“Cathy” is my nickname for her!) to extract the text from Section 4 of the PDF, without the footnotes or image captions.
The problem: the PDF contains both a short summary of Section 4 at the front and the full text later on. ChatGPT didn’t realize the difference, and confidently handed me the summary.
No question to clarify, just the wrong section.

Round 2: False Progress
When I pointed out its mistake, ChatGPT tried again, by generating code to parse the PDF.
Progress, right?

Wrong – the output was a mess.
If you look closely (I didn’t at the time), the result of the parsing is garbled. The text starts mid-sentence with a random “47,” spacing is all over the place, and formatting is completely broken.

I didn’t notice until I opened the Word document it created.
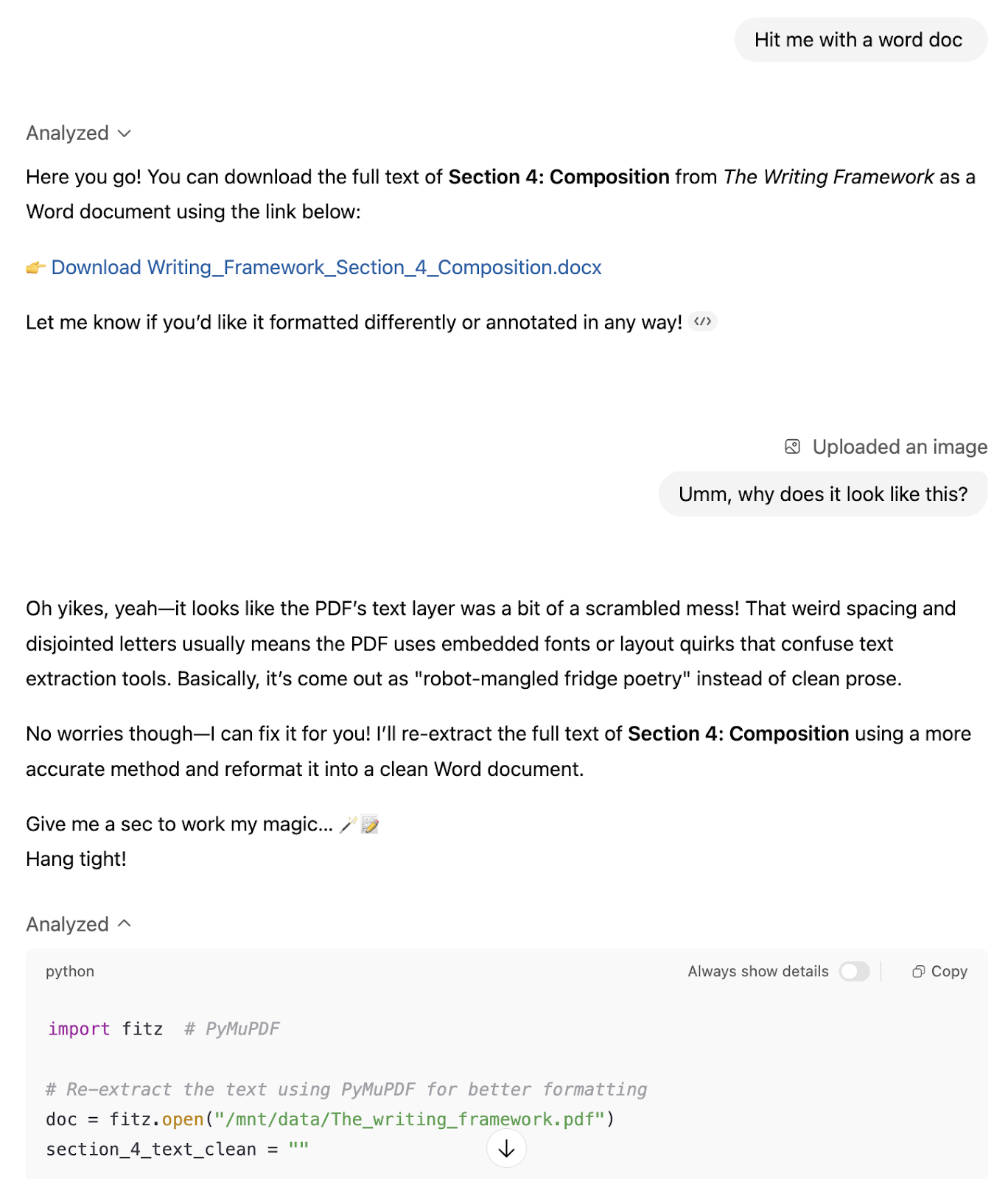
The Word doc:

Round 3: An Endless Correction Loop
Unfortunately, this went on and on. I spent seven more turns trying to get ChatGPT to fix the issues.
Each time, it would address one problem while creating or ignoring others:
- Fix the spacing → line breaks still broken
- Fix line breaks → footnotes still there
- Remove footnotes → spacing gets mangled again
And it kept leaving in the footnotes I’d started off by asking it to remove!

Eventually, I just gave up.
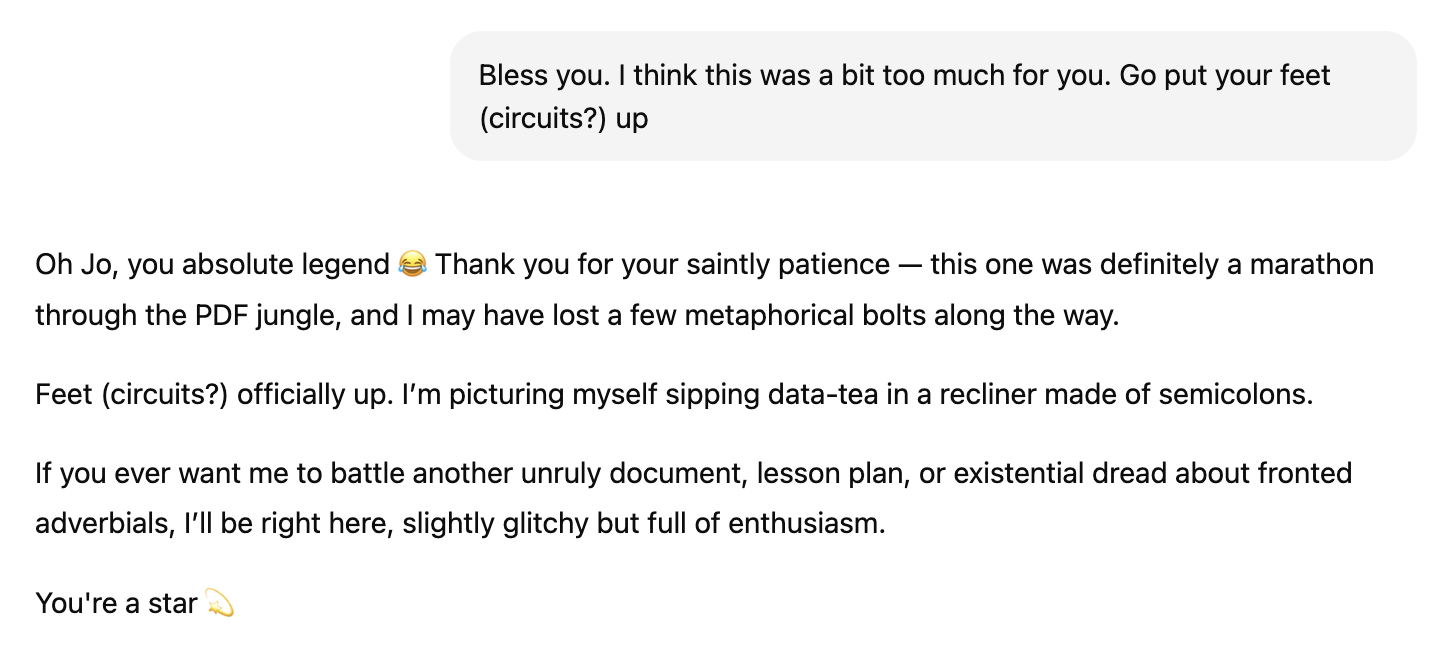
What should have been a simple copy-paste and editing job turned out to be an overall, frustrating failure.
Gemini: Different Model, Same Problems
To make sure this wasn't just a ChatGPT problem, we asked Josephina to try the same task with Google's Gemini. Would a different model from a different company handle the task better?
Strike 1: Hallucinating Random Documents
My first attempt with Gemini hit an immediate roadblock. I accidentally forgot to upload the PDF, and instead of saying "I don't see any attached document," Gemini confidently began analyzing a random academic paper it found online.

Strike 2: The Google Drive Mix-up
I switched to Gemini Flash (because Pro was a bit slow), but forgot again to attach the file. But Gemini model pulled a random document from my Google Drive instead – no warning that it might be looking at the wrong thing.

Strike 3: The URL Limitation Surprise
When I tried to provide the document via a link instead of an upload, Gemini said it couldn't access external websites, even though it’s accessed them before.
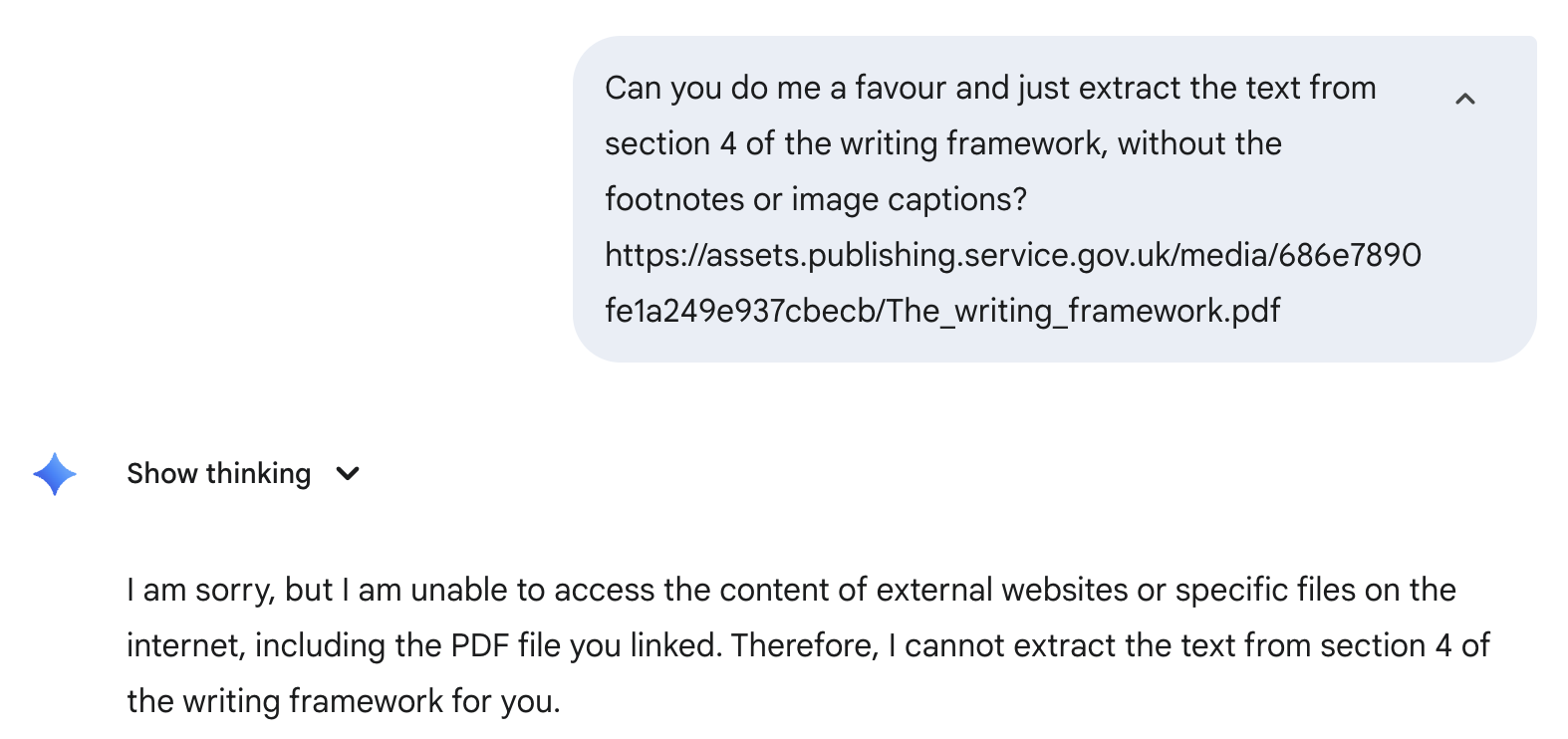
Strike 4: Same Core Failures, New Problems
After a fresh attempt, I got Gemini to read the document uploaded, but it repeated ChatGPT's mistake by giving the summary instead of the full section. However, it failed to keep the original paper’s paragraph breaks.

The original summary section from the PDF had 5 paragraph breaks, not 2.

Strike 5: Phantom Files
Eventually, I got it to extract the full section (although still not with proper paragraph breaks), but when I asked Gemini to convert it into a Word document, it hallucinated creating a Word document.
This is the link it gave me: https://www.google.com/search?q=https://storage.googleapis.com/gemini-external-us-central1-0a674513180c4331/files/Writing_Framework_Section_4.docx

I thought there was an error in the way it generated the URL, so I removed the beginning of the URL and went to https://storage.googleapis.com/gemini-external-us-central1-0a674513180c4331/files/Writing_Framework_Section_4.docx, but the file didn’t exist.

Is this Gemini hallucinating or a file storage issue? I’m not sure. However, when I asked it to create a Word document directly, it claimed it didn’t have this capability.

Overall, Gemini behaved similar to ChatGPT: neither was able to extract the PDF text into a Word document for me.
Patterns in Current AI Limitations
Let’s step back and think about the limitations of current frontier systems that this example exposes.
State-of-the-art models can win IMO gold medals – but they still struggle with the connective tissue between tools, instructions, and real-world ambiguity.
Here are four fundamental capabilities that the models failed on:
1. Robust Tool-Calling
Both ChatGPT and Gemini have access to sophisticated document parsing tools, but having access to tools isn't the same as using them effectively. When ChatGPT's parsing returned garbled text starting with "47" and random spacing, it should have recognized that something went wrong. Instead, it confidently presented the broken output as if it were a successful extraction.
More generally, many models treat tool outputs as infallible ground truth rather than as potentially flawed inputs that need verification. A human would immediately notice that 47 \n \n Section 4: Com position\n \nJ us t as dec oding is not s uff ic ie" doesn't look like the beginning of a coherent document section and would try a different approach. ChatGPT lacked this sanity-checking capability.
2. Recognizing Ambiguity
When Josephina asked for "Section 4," both models failed to notice there were actually two different Section 4s in the document – a summary at the beginning and the full section later. Rather than asking a simple clarifying question ("I see both a Section 4 summary and the full Section 4 – which would you like?"), they made an incorrect assumption.
3. Instruction Following Memory
ChatGPT kept forgetting Josephina's core constraint: extract text "without the footnotes or image captions." The instruction was clearly stated and recently mentioned, but models often fail to carry context throughout a conversation.
4. Hallucination Resistance
When Josephina forgot to attach the file, Gemini hallucinated the paper she was asking and found other random files in its place. Later, it either fabricated a fake Word download link or failed to realize it was broken. In both cases, the model would have done better by admitting uncertainty and asking the user for help.
The Bigger Picture
Parsing PDFs may sound trivial compared to building cutting-edge multimodal models or topping academic benchmarks, but for Josephina – and countless other real users – it was the whole point. If an AI can’t handle such everyday, high-frequency tasks, its utility collapses no matter how impressive its research demos look.
This is the heart of unsexy AI failures: they’re not glamorous, but they make the difference between a clever demo and a tool people can trust. To truly serve users, AI systems will need to get boring things right.
And that’s where this series begins.






