
Imagine you're building your dream search engine. How do you measure its performance, to make sure that it's delivering relevant, high-quality results?
Clickthrough rate may be your initial hope… But after a bit of thought, it's not clear that it's the best metric after all.
Take, for example, a search query to figure out how to programmatically delete a file. In the ideal search experience, users should never have to click since the query should be answered on the page itself!
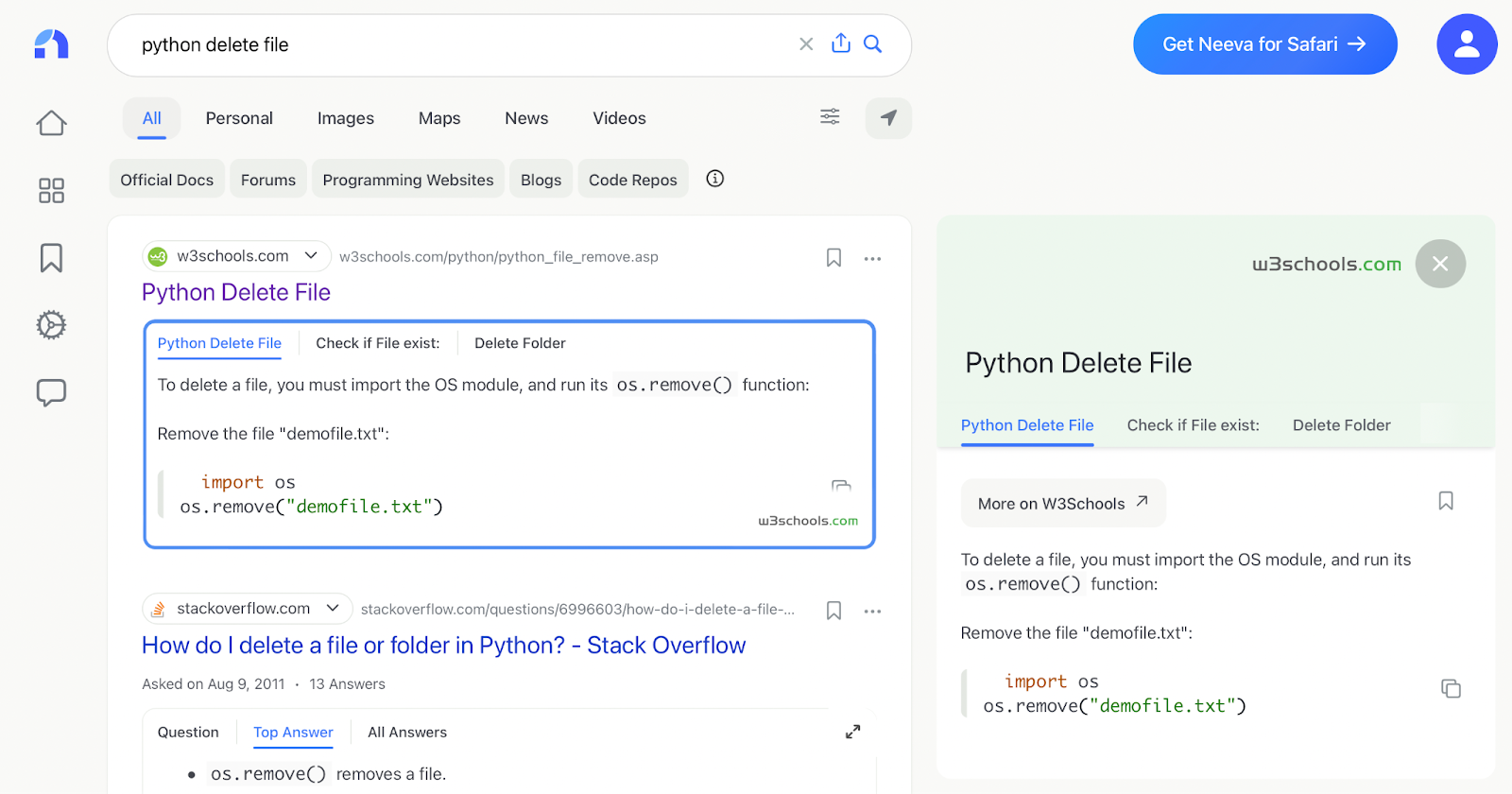
What about other metrics, like dwell time or number of searches? Could they be helpful instead?
Suppose you launch an experiment that accidentally starts showing racy-but-irrelevant content…
- Clicks will shoot through the roof!
- Number of searches will probably shoot through the roof too, as users reformulate their queries to find useful results.
- So might dwell time. After all, is dwelling on a page a sign that you’re finding it useful (hence why you’re staying on it), or not useful (you’re spending a long time scrolling to find information)?
- Overall, while the experiment might increase clicks and searches initially, it’s not optimizing user happiness or site quality for the long run.
What’s a search engine to do? Search Quality Measurement is one of the trickiest, but most important parts of building real-world search. If you don’t know which results are good, how do you train your models and decide which experiments to launch? It’s also extremely difficult: basing your search ranking algorithms on user engagement can lead to accidental clickbait instead of useful, efficient results.
This is why modern search engines use human raters as their backbone, showing them hundreds of thousands of pairs of queries and search results, and asking them to evaluate which ones are good or bad.
In this post, we’ll describe how Neeva uses human evaluation to train and evaluate their search ranking models – specifically in the advanced domain of technical programming queries.
Private, Ad-Free Search
Neeva is a new search engine founded by a team of ex-Googlers, designed to be private and ad-free.
Remember, after all, what Larry and Sergey wrote in their original Google paper, The Anatomy of a Large-Scale Hypertextual Web Search Engine:
“The goals of the advertising business model do not always correspond to providing quality search to users… Advertising funded search engines will be inherently biased towards the advertisers and away from the needs of consumers.”

For example, is a page full of ads what you really want to see when you’re sick and searching for a COVID test? (Or would you prefer to quickly see a map of the nearest testing location instead?)
Are you tired of seeing blinking advertisements and long-winded, SEO junk everywhere?
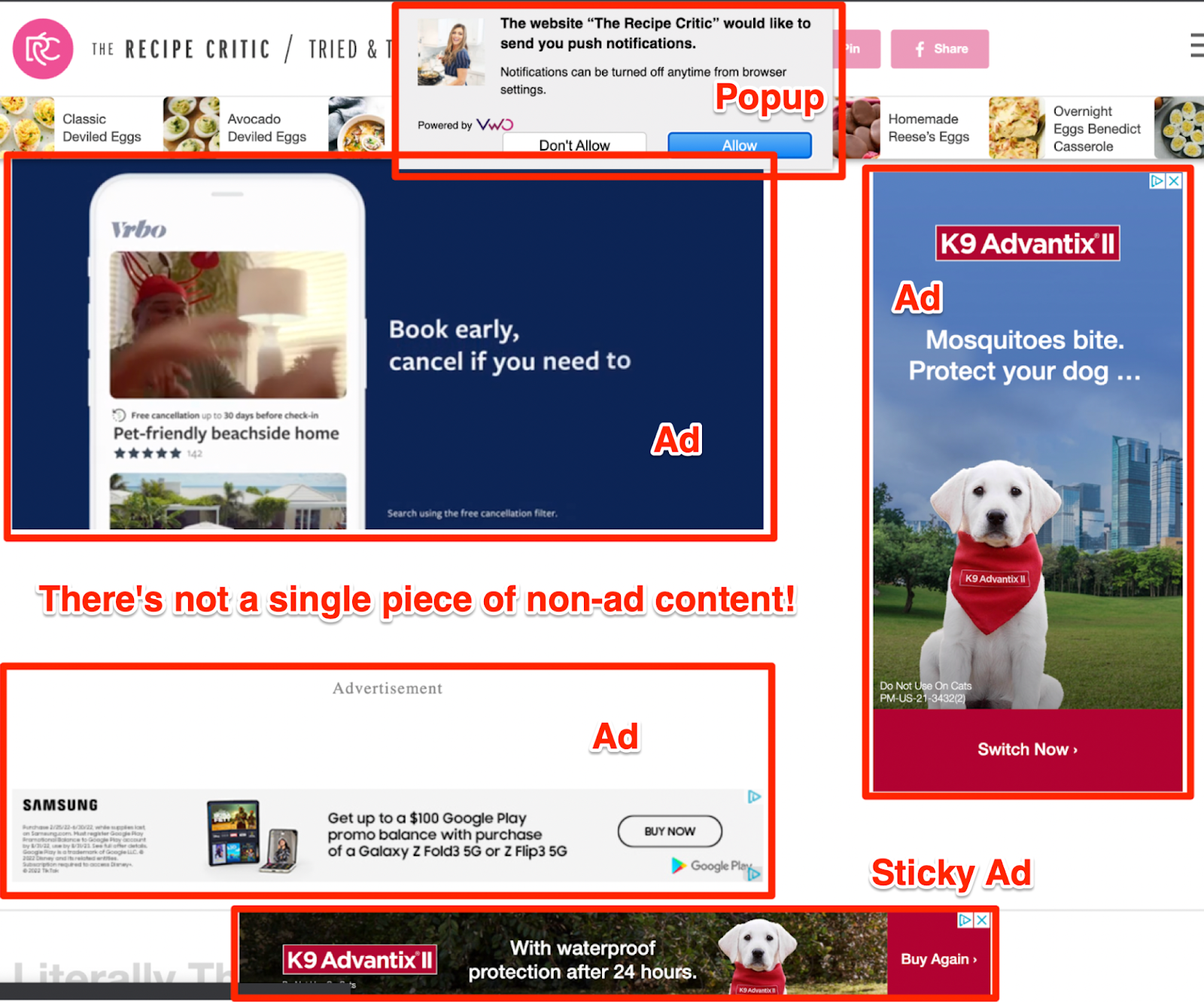
Clicks and engagement are very different from search quality and efficiency – pages full of ads and personal narratives may increase time spent (as you’re forced to navigate past the ads and stories), but they’re not what you want when you’re searching for a recipe on your lunch break. Human raters are the gold standard for telling the difference.
So in order to understand their strengths and weaknesses compared to Google, Neeva’s Search Ranking team ran a series of large-scale human evaluations of both search engines. This post describes one of them: a side-by-side evaluation of Neeva vs. Google on programming queries.
Side-by-Side Search Evaluation of Programming Queries
Imagine, for example, that you want to build a new search experience for software engineers. How do you understand their needs? To find out, Neeva ran a search evaluation comparing themselves against Google on technical programming queries.
Search Evaluation Challenges
Let’s first discuss some of the challenges of large-scale search evaluation.
Imagine that you’re a search rater, and you’re given the following query and search result links. Your goal is to score the relevance of each result.
Query: c++ iterator decrement past begin
Search Results to Evaluate:
- https://stackoverflow.com/questions/59040836/is-decrementing-stdvectorbegin-undefined-even-if-it-is-never-used
- https://cplusplus.com/forum/general/84609/
- https://www.geeksforgeeks.org/iterators-c-stl/
What are some of the challenges?
- If you’re not a programmer (or if you are, but don't know C++), do you know what the search query even means?
- How do you ensure that your search engine raters are doing a good job, and not merely marking answers at random?
- How do you label massive datasets quickly when your ML teams have sudden, spiky needs?
- Do you have good guidelines? How much should a result be penalized when it works for Python 2, but not Python 3?
- Are raters calibrated with each other? Is that calibration consistent over time?
- How does natural subjectivity of results factor into your quality controls?
- How do you know when your results are statistically significant, given multiple sources of bias?
- How do you build APIs and frontends that make it easy for ML engineers to launch new rating jobs?
Building a Technical Search Rating team
So imagine that you’re a search rater given a query like “c++ iterator decrement past begin”. If you’re the average person on the street, you have no way of understanding the intent behind the query!
Most Search Measurement and Data Labeling teams use the same generic raters for all queries, due to lack of good human computation infrastructure – but it’s impossible to evaluate search result relevance when you don’t even know what the query refers to. A rater good at rating Travel queries won’t necessarily be good at rating C++ queries too.
Luckily, we do a lot of work around teaching AI models to learn how to code. So to combat this, we took Surgers with programming backgrounds, measured their search evaluation abilities on a series of tests, and formed a programming-specific search rating team for Neeva.
For example, here are a few of these Surgers in their own words:
Matt R.
I'm an aspiring artist who has a deep love of all things Python. After graduating high school, I studied software engineering for five years as part of an engineering dual degree partnership. During my time in university, I studied and gained expertise in various programming languages (C++, C#, Python), in software project development and management, and in the math and sciences. However, I have since pursued a career in digital illustration and continue to do so. It has been an aspiration of mine for quite some time, and though it's a bit more volatile than continuing with software engineering, I find that I am much happier with my new direction. Nowadays, my coding is mostly directed at personal projects, with my current project being the development of an Android app that draws on both my coding and artistic expertise.
Sam B.
In college, I majored in both Computer Science and Creative Writing. During that time, I studied and worked in a bunch of different areas. You could say I'm a jack of many different trades. I did a lot of work with an online academic journal dedicated to Shakespeare and appropriation, helping them maintain their website and contributors' online submissions. I was also a Fellow for an organization called the Center for Science and the Common Good. We studied things at the intersection of science and morality, like climate change and genetic modification.
Forming a Personalized Search Evaluation Query Set
The next step in the evaluation was choosing a set of search queries to compare Google and Neeva on. There are several common choices:
- Query weighted: randomly sampling from the query stream of all user queries, weighting each query by the number of times it’s searched. This has the benefit of aligning your evaluation to overall performance.
- Uniformly weighted: randomly sampling from the query stream, weighting each distinct query equally. This has the benefit of biasing your evaluation to the long tail of queries (queries that are completely novel or only issued a few times, in contrast to popular “head” queries like “tom cruise”). This can be helpful since tail queries tend to be more difficult for a search engine to get right.
- Personalized: asking Surgers to pick queries from their own browser history. This has the benefit of raters knowing exactly the intent behind each query, and being able to provide much more detailed and personalized feedback on why each search result solved their needs or not.
Since we would eventually run all three choices of query sets, we decided to start with #3 – a personalized search evaluation where Surge raters would rate results for their own queries – since it would provide more detailed feedback on user needs.
For example, here were some of the personalized queries that Surgers pulled from their histories:
Query: javascript join two arrays
Intent: I wanted to find the code necessary to join two arrays in JS.
Query: why switch from bash to zsh
Intent: I have seen some discussions about using zsh instead of bash, so I wanted to see what the pros and cons of switching would be.
Query: yarn add from host permission error docker
Intent: I was working on a project and I was getting permission errors when trying to add Node packages from outside the Docker container. I wanted to know what was causing this.
Search Evaluation Task Design
The next step was designing the evaluation: what exactly would the Surge raters be evaluating, and what kinds of labels would they be generating? Here were some of the design questions that arose:
Rating scale. What rating scale should raters evaluate search results against? For example, should it be a 3-point Likert Scale (Good, Okay, Bad) or a 10-point one? Should there be asymmetric call-outs for particularly WTF or Vital search results?
What evaluation questions did we want to ask? For example:
- Did we only care about the relevance of the search result to the query?
- Did we care about the quality of the search result page (e.g., whether it loaded slowly or showed too many ads)?
- Was page authority important?
- Did we want to focus on pure ranking relevance, or did we care about the UI of the search result on the SERP too?
The pro of focusing on search relevance is that it focuses on data that’s most useful to the Search Ranking team. The con is that it ignores all the other factors (UI, great summary snippets, fast loading times of the results, etc.) that go into making a great search engine.
Individual search results vs. SERP. Did we want raters to evaluate each individual search result in isolation, or to evaluate the entire SERP as a whole? The benefit of evaluating each individual search result is that it gives you finer-grained metrics and training data. The cons are that it ignores factors like diversity, and it’s difficult to combine them into a SERP-level score (NDCG, despite its prevalence in Information Retrieval 101, often isn’t a great metric!), which is what users experience.
Absolute vs. side-by-side ratings. Should raters judge each search engine in isolation, or compare them? For example, Neeva and Google may both perform well on a query, but one of them may be slightly better. In such scenarios, it’s often hard for raters to distinguish between Neeva and Google when rating each in isolation, but much easier when comparing them directly.
After much experimentation, we went with a 5-point Likert scale, rating both the top 3 search results and the SERP for overall satisfaction (combining relevance, quality, authority, and any other factors as a whole). If you’re interested in a sample of the dataset, explore it in our results viewer here!
Developer Search Eval Examples
After running the side-by-side evaluation, what did results look like? Here are some example ratings.
Example #1: Neeva Wins
Search Query: list of dictionaries to dataframe pandas
Search Intent: I was trying to see how to convert a list of dictionaries into a pandas dataframe.
Google Rating: Pretty Good. The top Google result answered my question, and most other results displayed would have answered the question as well. Although oddly, the second result was on a site largely about an Apache Spark tutorial, which felt out of place.
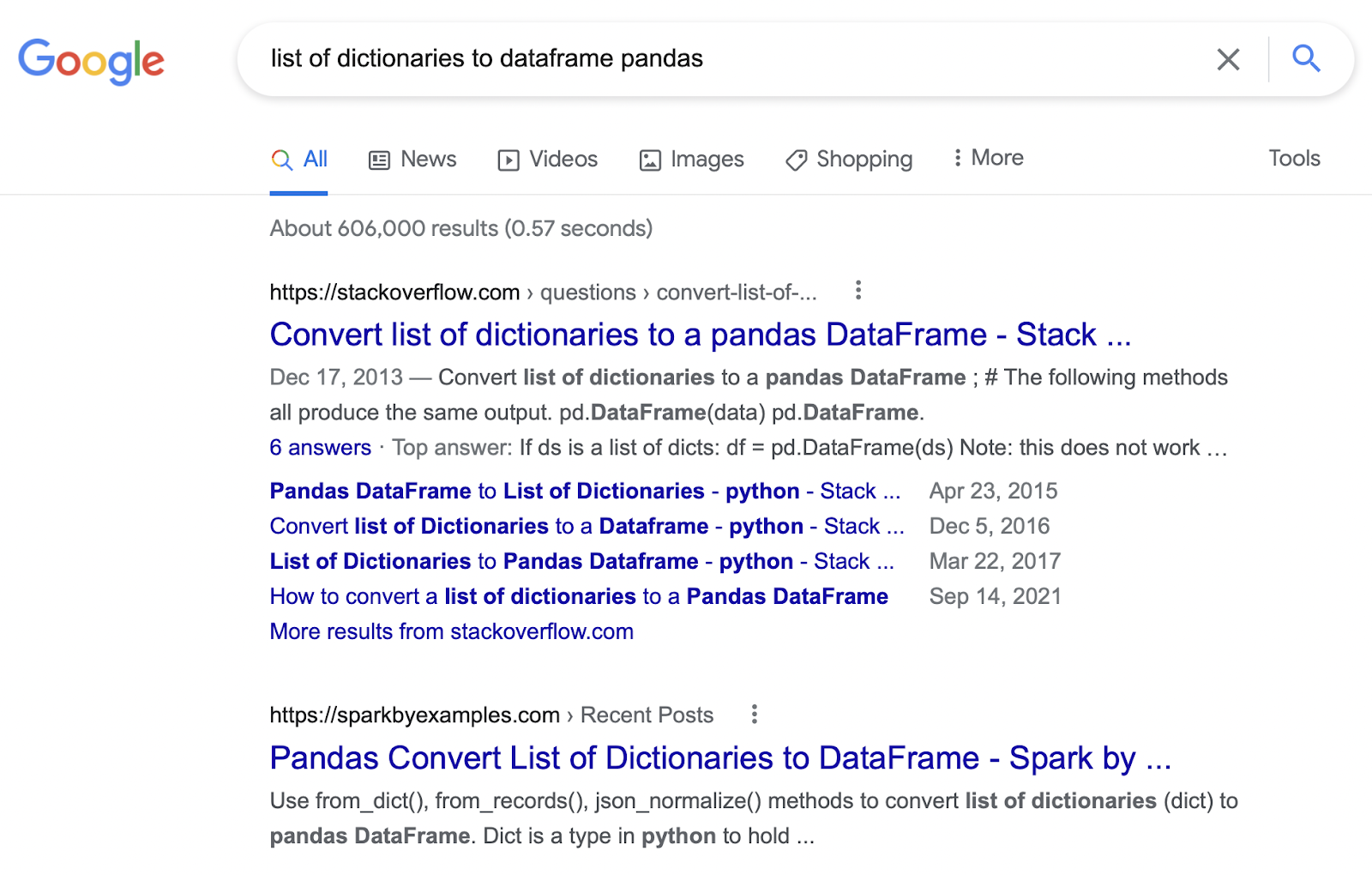
Neeva Rating: Amazing. The top answer was shown directly under the link to the Stack Overflow post as a snippet, which made it easy to see and use the answer to the query. It also has a copy feature that allows you to copy the code directly from the search results. Very cool. The other query results were relevant as well.
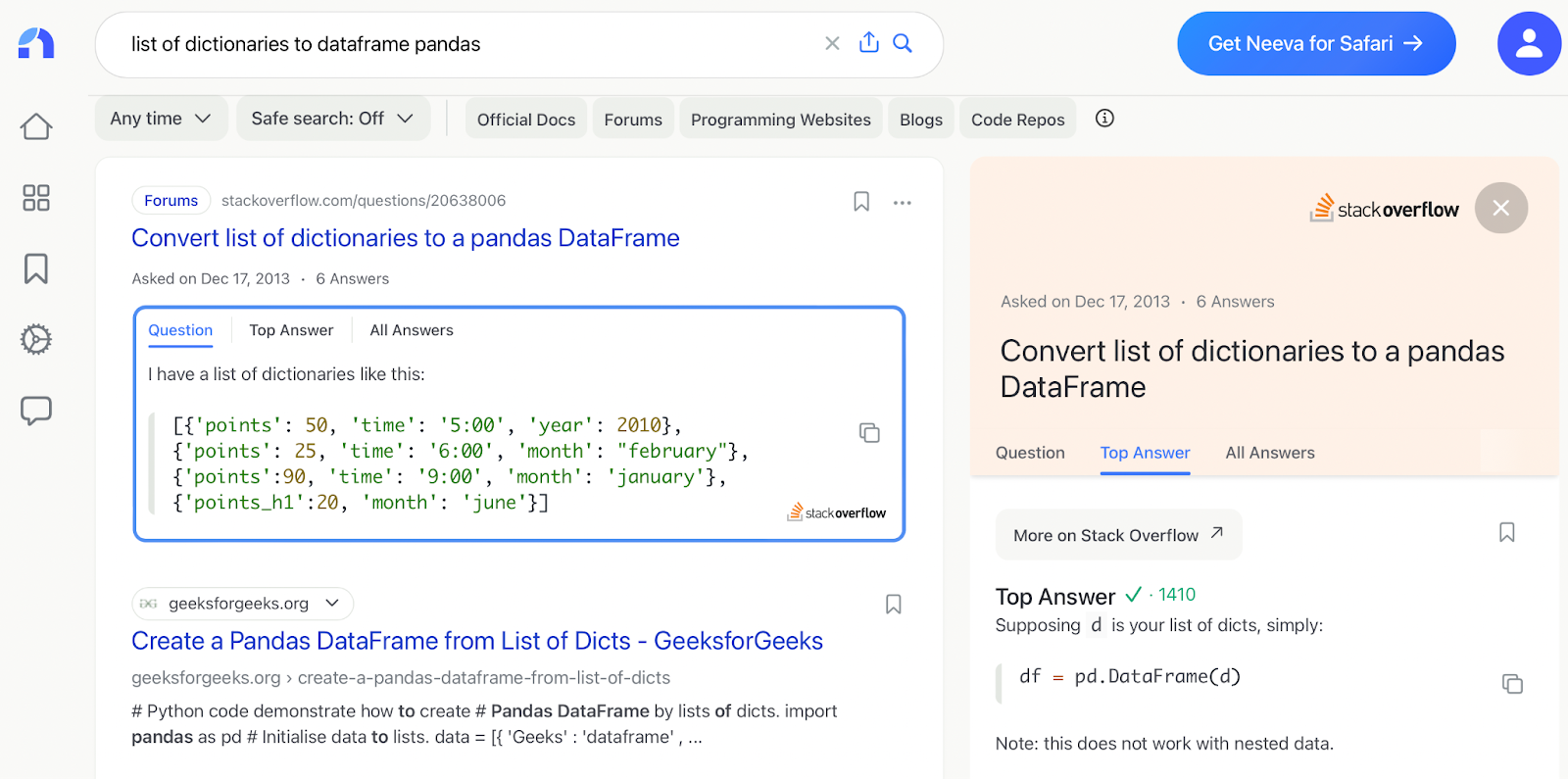
Overall Google vs. Neeva Rating: Neeva is much better. Google and Neeva did have basically the same results, but the fact that Neeva had a snippet of the solution to the answer that one could copy directly off the search results page was very convenient.
In this example, the searcher appreciated Neeva’s rich user experience, since it makes it much easier to find the answers they want.
Example #2: Google Wins
Search Query: how to use return in lambda function in python
Search Intent: I wanted to see how and if you could use a return statement in a lambda expression. Ideal result would be an example or explanation on the topic with examples on how to do it.
Google Rating: Amazing. The results provided exactly what I wanted, which was examples and explanations on my search query. The "people also ask" area was useful as well because it answered some questions I didn't know I needed the answer too, but was still relevant to the original search query.

Neeva Rating: Okay. The first couple results were related to how to use lambda expression in general, and not about my specific search query on using lambda with return statements. I had to dig through the results to find an answer to my specific question and not just generally how to use lambda.
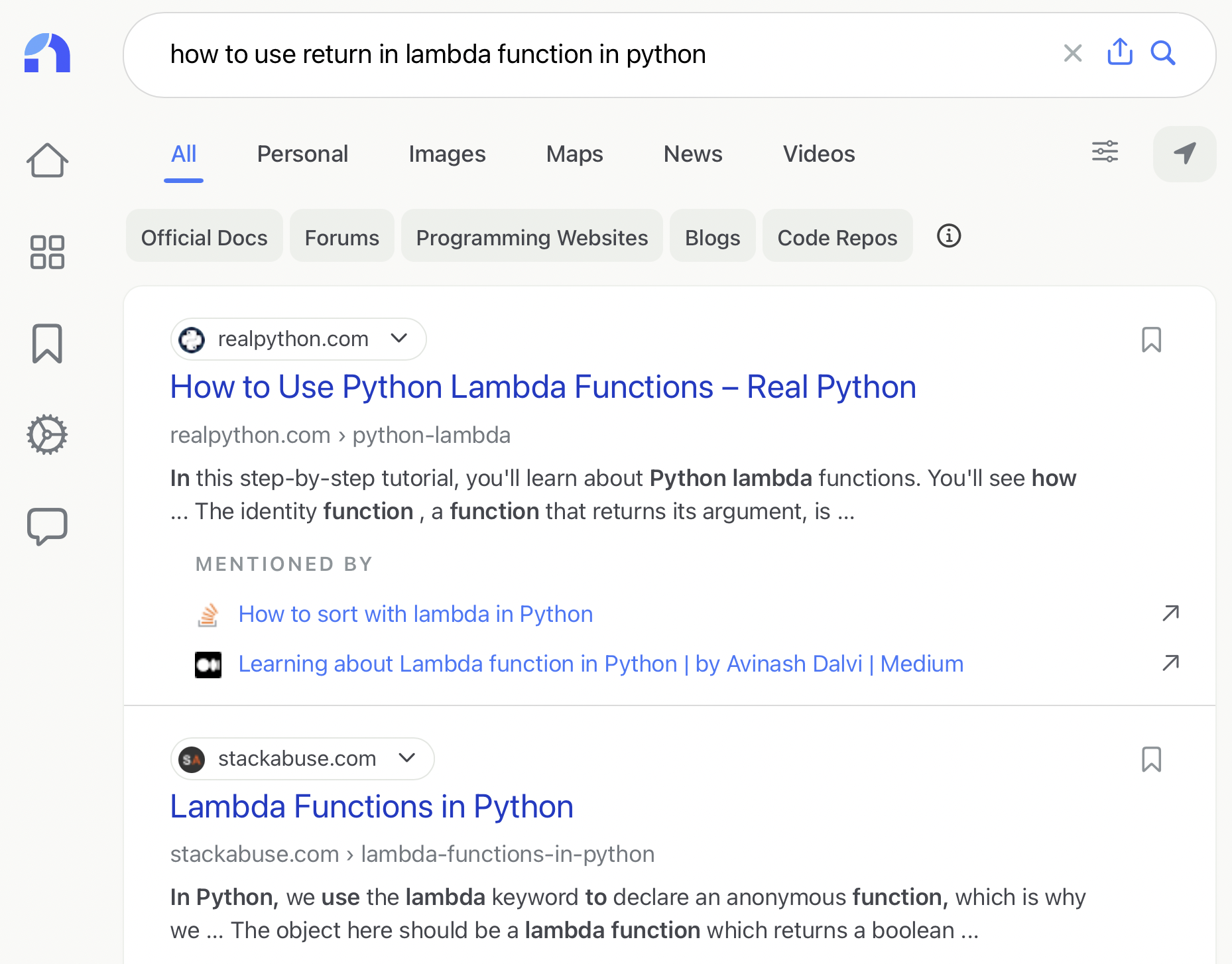
Overall Google vs. Neeva Rating: Google Much Better. Google's results were more relevant in answering the query of how return works with lambda in python. Neeva had results on how to generally use lambda and was not focused on my specific query.
In this example, the searcher found Google’s relevance and query understanding much better.
For more examples, check out the side-by-side evaluation results on our rating platform here.
Applications, Insights, and Future
What kinds of applications does the ability to run large-scale human evaluations enable for Search and ML teams?
- Offline Experimentation. Traditional online A/B tests are difficult for Search Engines to run. First of all, are you hoping that metrics like clicks, dwell time, and searches will increase or decrease? Some great experiments will increase them; other great experiments will decrease them. Second, like all online A/B tests, you often need to wait weeks for them to run in order to gather trustworthy metrics. One alternative is human evaluation A/B tests: you form a query set, scrape results from both control and experiment for each query, and run a side-by-side human evaluation where raters score which side performs better. This enables statistically significant results in hours, instead of weeks.
- ML Training. The human-labeled queries and search results form rich, high-quality datasets that you can train your machine learning search algorithms on.
- Golden Sets and OKRs. Many search engines, at the start of every quarter or every year, form large “golden sets” of queries that they want to optimize on, and then measure their performance on this golden set every week. For example, their goal may be to improve their human eval scores on the golden set by 25% every quarter.
- Data Science Insights. One of the insights that Neeva learned was that in 80% of cases where Neeva performed much better than Google, it was because of their rich widgets and intelligent answers. In contrast, in 80% of cases where Google performed much better than Neeva, it was because of better long tail query ranking.
Interested in learning more about Search? Follow @Neeva on Twitter, where they share real-world Search Ranking wisdom and behind-the-scenes details on their custom Search Infrastructure stack.
And if you're interested in learning more about human evaluation and high-quality data labeling, follow @HelloSurgeAI on Twitter, or reach out to us at hello@surgehq.ai to chat!






