
In theory, AI has blown past our wildest dreams; in practice, Siri can’t even tell us the weather. The problem? Creating high-quality datasets to train and measure our models is still incredibly difficult. We should be able to gather 20,000 labels for training a Reddit classifier in a single day, but instead, we wait 3 months and get back a training set full of spam.
Surge AI is a team of Google, Facebook, and Twitter engineers and researchers building human-AI platforms to solve this. Need help building trustworthy datasets, or interested in a higher-quality Mechanical Turk? Reach out at team@surgehq.ai (or @HelloSurgeAI on Twitter)!
Four years ago, AlphaGo beat the world’s Go experts, big tech was acquihiring every ML startup they could get their hands on, and the New York Times declared that “machine learning is poised to reinvent computing itself”.

It felt like we were just a few years away from a world where Alexa would take over our homes, and Netflix would give us better movie suggestions than our friends.
👀 What’s happened since then?
Faster GPUs have dropped the cost of training neural networks and allowed for larger and larger models to be trained. New tools make the infrastructure work much easier.
We’ve also developed new neural network architectures that learn to perform more subjective tasks. Transformers, for example, power OpenAI’s GPT-3 model, a language generator that writes blog posts that reach the top of Hacker News.
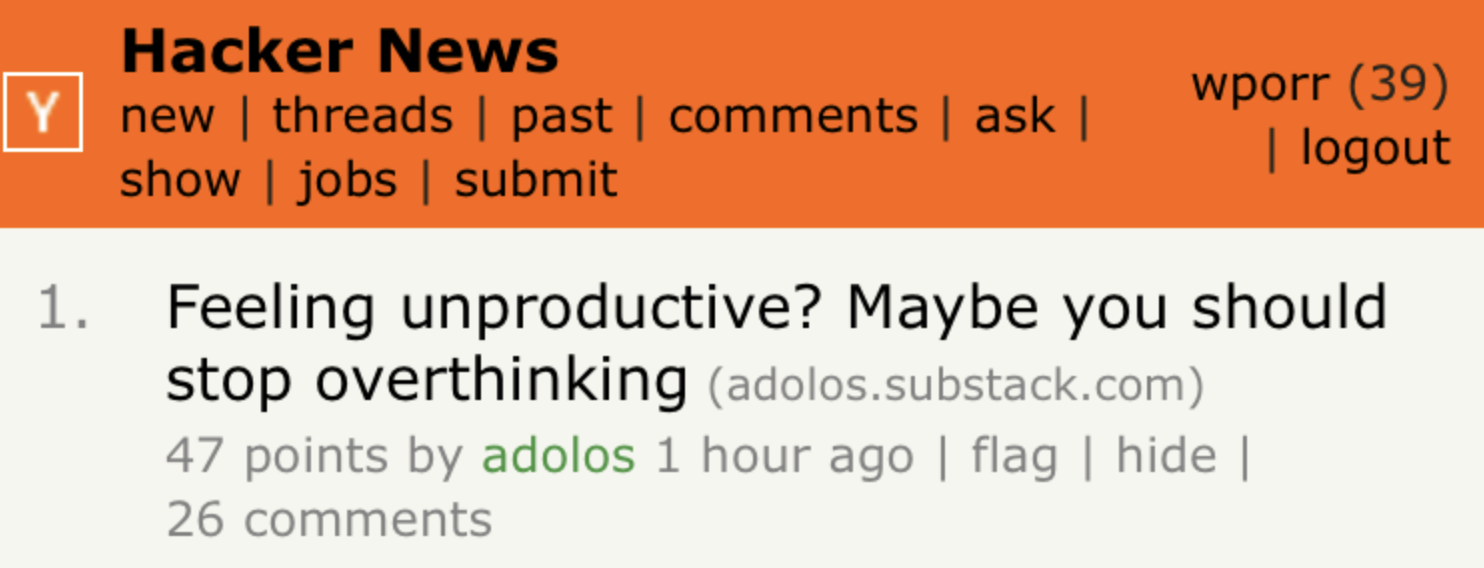
https://liamp.substack.com/p/my-gpt-3-blog-got-26-thousand-visitors
Then where’s the revolution?
So why hasn’t AI taken over the world?
- 🧯 Why can I generate a blog post with GPT-3 — but social media companies struggle to keep inflammatory content out of our feeds?
- 🥯 Why do we have superhuman Starcraft algorithm — while e-commerce stores still recommend I buy a second toaster?
- 🎬 Why can our models synthesize realistic images (and movies!) — but fail at detecting faces?
The short answer: our models have gotten better but our data hasn’t. Our models are trained on (and measured against!) datasets that remain error-ridden and poorly aligned with what creators actually want.
What’s wrong with today’s data? Garbage in, garbage out 🦝
In some cases, models are trained on proxies like clicks and user engagement.
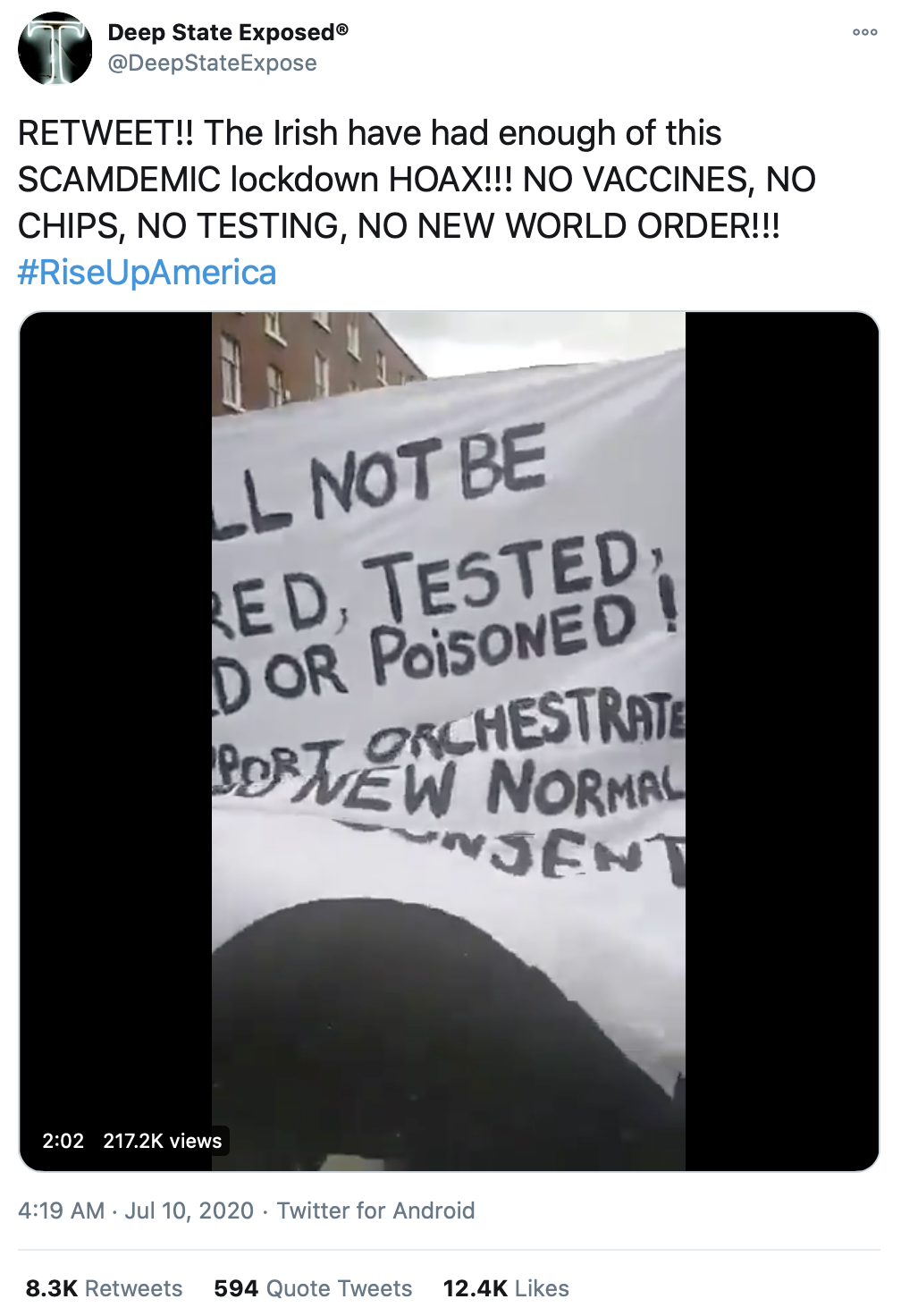
Social media feeds, for example, aren’t trained to provide users the best experience; instead, they maximize clicks and engagement, the easiest sources of data available.
But likes are different from quality — shocking conspiracy theories are addictive, but do you really want to see them in your feed? — and this mismatch has led to a host of unintended side effects, including the proliferation of clickbait, the spread of political misinformation, and the pervasiveness of hateful, inflammatory content.
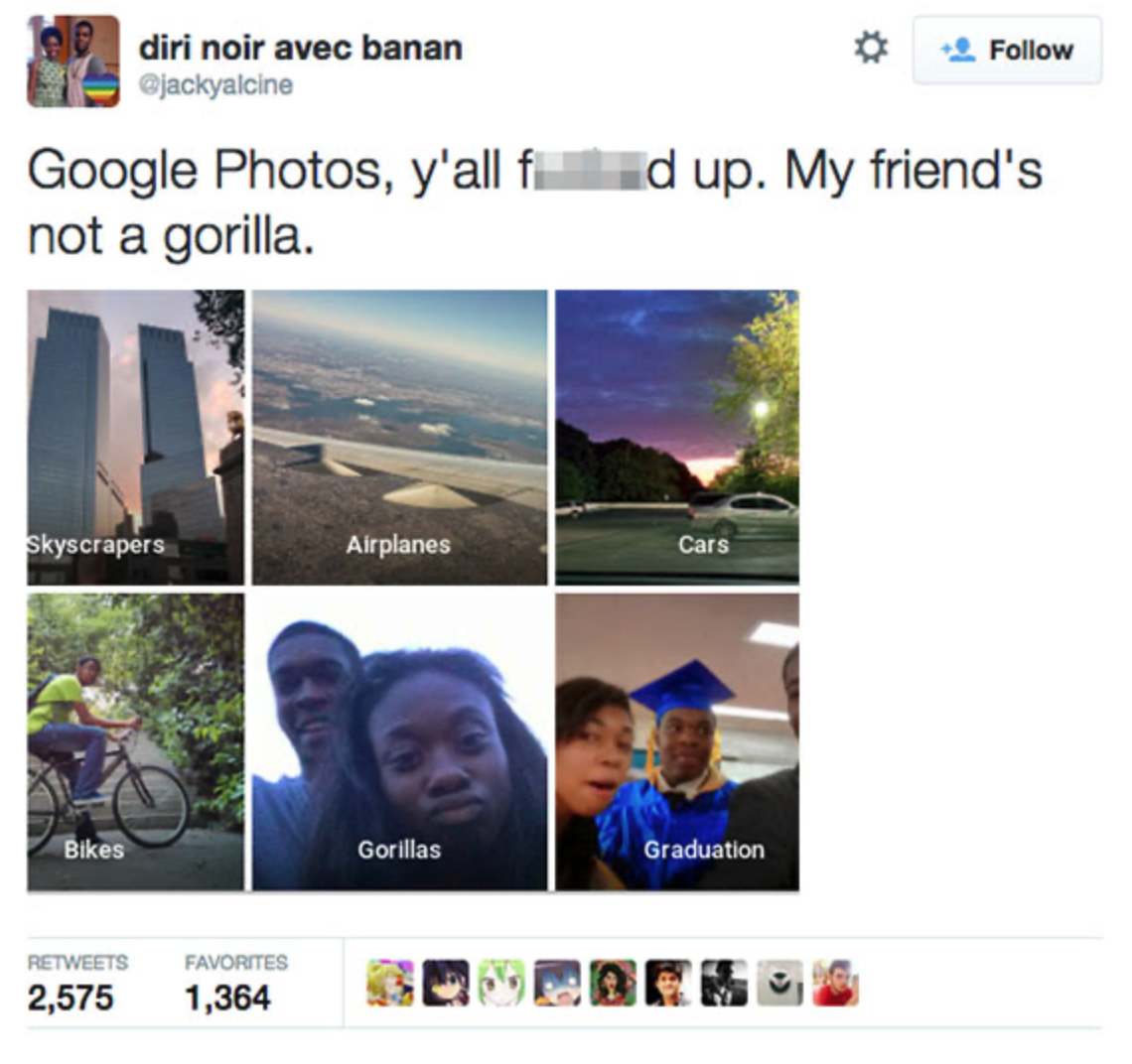
At other times, models are trained on datasets built by workers who don’t work in their native language or who know that low-quality results will never be detected.
Take, for example, the following tweet.

A typical labeler will spot “bitches”, “fucking”, and “shit”, and label this tweet as toxic, even though the profanity is intended in a positive, uplifting manner. We’ve run into issues like these in our training sets countless times.
Data defines the model. If the data is mislabeled garbage, no amount of ML expertise will prevent the model from being junk as well.
🧗 What advancements do we need?
Dataset issues cause a host of problems.
When faced with poorly performing models, engineers spend months tinkering with features and new algorithms, without realizing that the problem lies with their data. Algorithms intended to bring friends and family together drive red-hot emotions and angry comments instead.
How can we fix these problems? Here are a set of building blocks we believe are critical for unlocking the next wave of AI.
🎒Skilled, high-quality labelers who understand the problem you’re trying to solve
As AI systems become more complex, we need sophisticated human labeling systems to teach them and measure their performance. Think of models with enough knowledge of the world to classify misleading information, or algorithms that increase Time Well Spent instead of clicks.
This level of sophistication can’t be boosted from majority votes on low-skill workers. In order to teach our machines about hate speech and to identify algorithmic bias, we need high-quality labeling forces who understand those problems themselves.
💃 Spaces for ML teams and labelers to interact
ML models are constantly changing. What counts as a spammy email today may not tomorrow, and we’ll never capture every edge case in our labeling instructions.
Just as building products is an feedback-driven process between users and engineers, dataset creation should be as well. When counting faces in an image, do cartoon characters count? When labeling hate speech, where do quotes fall? Labelers uncover ambiguities and insights after going through thousands of examples, and to maximize data quality, we need both sides to communicate.
Objective functions aligned with human values
Models often train on datasets that are merely an approximation of their true goal, leading to unintended divergences.
In AI safety debates, for example, people worry about machine intelligences developing the power to threaten the world. Others counter that this is a problem for the far future — and yet, when we look at the largest issues facing tech platforms today, isn’t this already happening?
Facebook’s mission, for example, isn’t to garner likes, but to connect us with our friends and family. But by training its models to increase likes and interactions, they learn to spread content that’s highly engaging, but also toxic and misinformed.
What if Facebook could inject human values into its training objectives? This isn’t a fantasy: Google Search already uses human evaluation in its experimentation process, and the human-AI systems we’re building aim to do the same.
🤖 A human-powered AI future
At its core, machine learning is about teaching computers to perform the job we want — and we do that by showing them the right examples.
So in order to build high-quality models, shouldn’t building high-quality datasets, and making sure they match the problem at hand, be the most important skill of an ML engineer?
Ultimately, we care whether AI solves human needs, not whether it beats artificial benchmarks.
If you work on content moderation, are your datasets capturing hate speech — or positive, uplifting profanity too?
If you’re building the next generation of Search and Recommender Systems, are your training sets modeling relevance and quality — or addictive misinformation and clicks?
Dataset creation isn’t something taught in schools, and it’s easy for engineers who’ve spent years studying algorithms to fixate on the fanciest models in arXiv. But if we want AI that solves our own real-world needs, we need to think deeply about the datasets that define our models, and give them a human touch.
Surge AI is a team of Google, Facebook, and Twitter engineers building platforms to enable the next wave of AI — starting with the problem of high-quality supervised data.
This requires humans and technology working together. Our high-skill labeling workforce undergoes a rigorous series of tests; our platform then makes trustworthy data collection a breeze. Together, we’ve helped top companies create massive datasets for misinformation, AI fairness, creative generation, and more.
Tired of low-quality datasets, or interested in a Mechanical Turk that actually works? We’d love to hear from you.






