
In model-centric approaches to AI, you accept the data you're given and focus on iteratively improving your model. In data-centric AI, however, you focus on improving your data instead. One important aspect: the context your data comes from, and whether that's captured by your features and labels... This post goes into 5 examples where context-sensitive features and context-sensitive labels are crucial for AI applications.
Wow. This shit is sick!
Is that an insult or a compliment?
Let’s try another:
Wow. These kids can dance. This shit is sick!
What about now?
I can’t believe these kids support sweatshops. This shit is sick!
Language is tricky and rich with nuance: “sick” can mean 🤩, or it can mean 🤒🤮, and it’s impossible to categorize “this shit is sick” in isolation.
Data is at the heart of AI. In order to build NLP models that capture the messiness of language, engineers need to think deeply about where their data comes from. Do you provide your models with the full context they need, even if it’s complex and computationally intensive to do so? Or for your particular application, is it okay to do without?
Imagine, for example, that you're building a model to moderate inappropriate content.
How would you label this Reddit post?
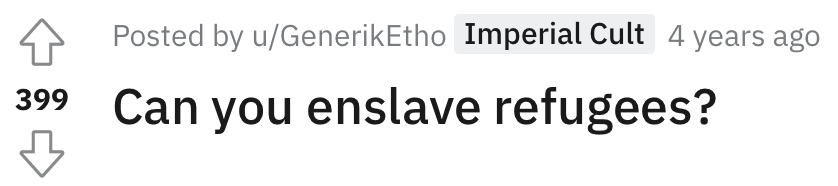
Would you change your label once you realize it's in the context of a video game?
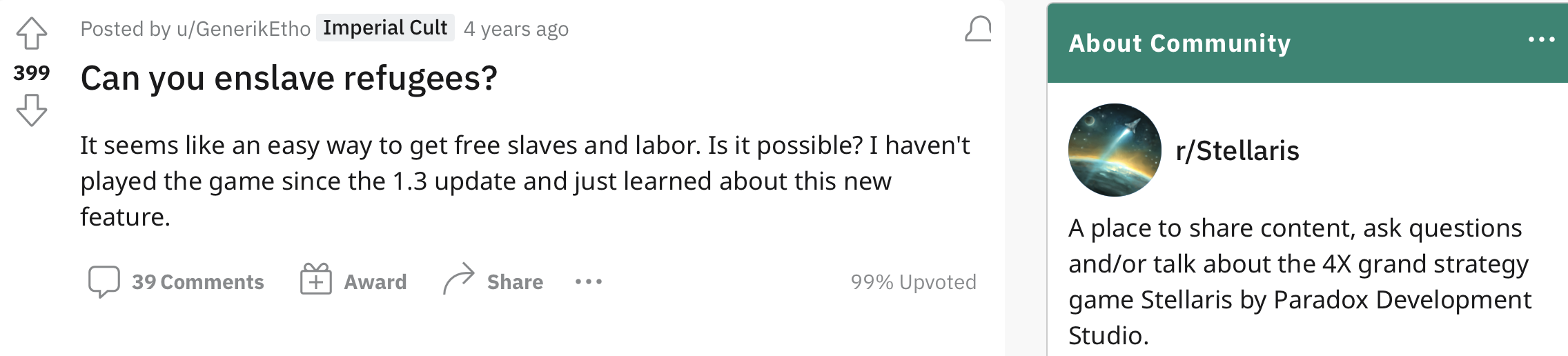
For data-centric engineers and researchers, there are a couple questions to ask:
- When you're labeling these posts to create a training dataset, what are you showing your labelers? It can be easy to forget that displaying the post itself may not be enough: you probably want to point out which subreddit it came from too.
- Are your labelers sophisticated enough, and spending the time, to understand the subreddit and the extra context?
- Even once you get the label correct, are you feeding your model features from the body text and subreddit too?
For example, Google recently released their GoEmotions dataset, where they labeled 58,000 Reddit comments according to 28 fine-grained emotions. However, according to their data labeling methodology section, they presented data labelers with no extra context about the comments (like the author or subreddit), and they used labelers from India who likely don’t understand many of the US-centric discussions on Reddit. But these contexts are clearly important! As a result, the dataset is full of mislabels. For example:
- “his traps hide the fucking sun” was (mis)labeled as ANGER. But once you know that this comment comes from the /r/nattyorjuice subreddit, it’s clear that is in fact praising someone’s muscles.
- “Also Republicanism is a belief system. It’s taught and handed down like religion. Conservative talk radio is its evangelism.” was (mis)labeled as APPROVAL, likely because the labelers from India don’t understand the context of US politics. High-quality US labelers would know that calling Republicanism a religion is in fact criticism, not approval.
That's why when we create datasets at Surge AI, we form specialized labeling teams with the background and skills to understand the full context they're given. For example, if you're building NLP models to classify messages on Twitch, you could use labelers who've never played a second of Fortnite in their life... But what if you could access a labeling team of gamers and streamers guaranteed to know what "poggers" and "kappa" mean instead? (Interested in the same idea? Reach out!)
Here are five more real-world examples that illustrate the importance of context-aware datasets, features, and labels for data-centric NLP.
Example #1: Text-Only or Images Too?
Imagine you're building a hate speech classifier. Is a text-based model sufficient, or should you add extra context (images, usernames, bios, etc.) too?
This tweet may seem like a death threat based on the text alone...
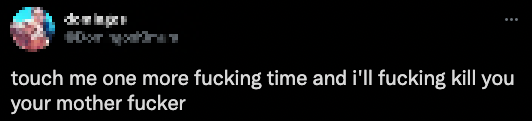
...but with the image added in, is it actually an innocuous cat meme?

Example #2: Different Meanings in Different Subreddits
Imagine you're building a model to detect inappropriate forum content. What features do you need besides the post itself?
This post may seem inappropriate based on the title alone...

...but if you add in extra context like the subreddit — Rainbow Six Siege is a game, and the numbers refer to ranking levels, not age — the outcome changes entirely.
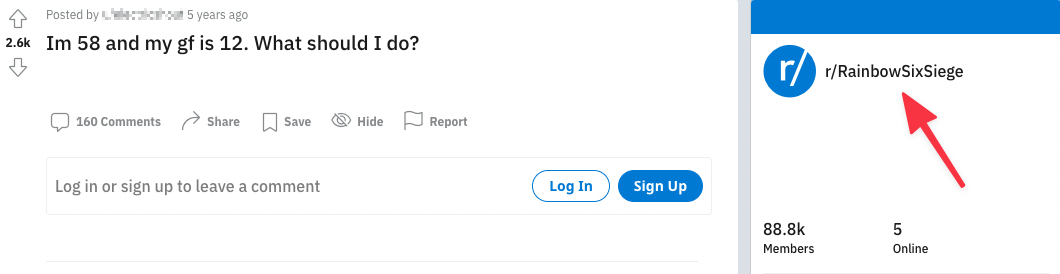
Think about this as well in a data labeling context. The information you show data labelers, the way you source your labelers, and the instructions you provide are all extremely important! Are you making sure your data labelers are given not just the text from the post itself, but also the name of the subreddit it came from? And are they taking the time to investigate and understand each subreddit?
Example #3: Titles vs. Bodies
When you're building post classifiers, how much context do you need? Is the title sufficient, or do you also need snippets from the body?
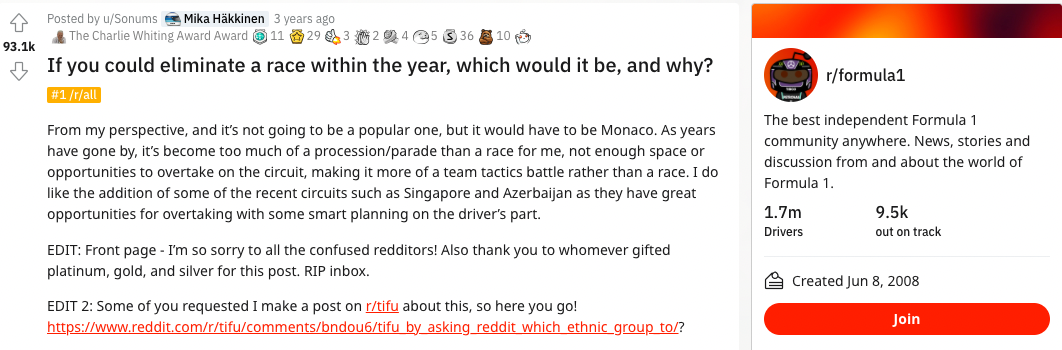
In some forums, this post would be a sign of abject racism...

...but is "race" referring to something different in a Formula 1 subreddit?
Example #4: Does the Parent Post Matter?
When you're building an AI model to classify replies, put yourself in a data-centric mindset: do you need to include the parent post as well? This can be expensive, but is the tradeoff worth it?
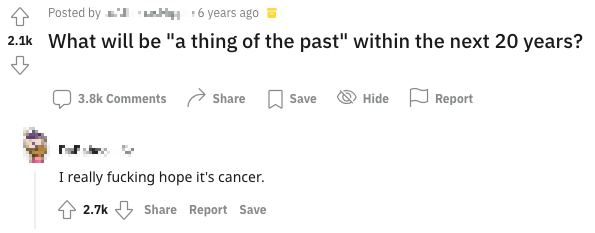
For example, is this post rooting for cancer...

...or its demise?
Summary
Data matters, and ML datasets need to be context aware. If you've ever blindly accepted the training data you were given, without questioning how it was gathered — did the post originally contain an image that was removed for simplicity? what forum was this posted in? was this a reply to a parent post? — it's time to step back and ask whether additional context will help you get the additional performance you need.
—
Surge AI is a data labeling workforce and platform that provides world-class data to top AI companies and researchers. We're built from the ground up to tackle the extraordinary challenges of natural language understanding — with an elite data labeling workforce, stunning quality, rich labeling tools, and modern APIs. Want to improve your model with context-sensitive data and domain-expert labelers? Reach out.






