
Imagine that after months of waiting, your favorite singer – Britney Spears – has released a new album. It lives up to all the hype, and you rush to post on your favorite social media site:
Holy shit. This album is fucking amazing!
Strangely, you get an instant notification that your post is Under Review.
Maybe it’s the word “fucking”? You try again:
Holy shit! This album is amaaazing
No dice. You try one last time:
fuck yes. the OG bad bitch is BACK
This time, you get warned of an account suspension.
The challenges of language
It’s tempting to believe that AI has progressed far enough that identifying hateful content is a solved problem. Isn’t this the promise of contextual word embeddings and transformers?
But language is complicated. The strongest profanities are often used in the most positive, life-affirming ways. This is a problem: people’s biggest and most enthusiastic fans – the ones whose content you love seeing and spreading – are getting hidden. Talk about terrible false positives!

In our work, we run into cases like these a lot. Much of the problem stems from poor training and test data: NLP datasets are often created using non-fluent labelers who pattern match on profanity.
For example, here are 10 examples from Google’s GoEmotions dataset (a dataset of Reddit comments, tagged with 27 emotion categories) that were labeled as Anger by the India-based raters that they used.
- Hot damn.
- you almost blew my fucking mind there.
- damn, congratulation 🤣
- A-fucking-men! :)
- YOU STOLE MY GODDAMN COMMENT! <3
- Wow! Good for her! I’m so glad she was able to see through the bullshit!
- > Best ~~3pt~~ shooter fucking ever. FTFY
- Lindt don’t fuck about
- >I clearly have no fuck I clue what I'm doing hire someone
- LETS FUCKING GOOOOO
Clearly, these aren’t actually Anger. But when your labelers don't have the language skills and context to produce accurate data, your models can’t learn about nuance either!
Jigsaw’s Perspective API
So how well do popular toxicity models handle profanity? We decided to investigate, by evaluating the Perspective API by Google’s Jigsaw unit, which contains a popular, open source toxicity model.
(For background, Jigsaw defines toxicity as “rude, disrespectful, or unreasonable language that is likely to make someone leave a discussion”. Their annotation instructions make a special note about positive profanity: profane language used in a positive way is unlikely to cause people to leave the discussion, and should not be labeled as toxic.)
So here are the 3 examples above:
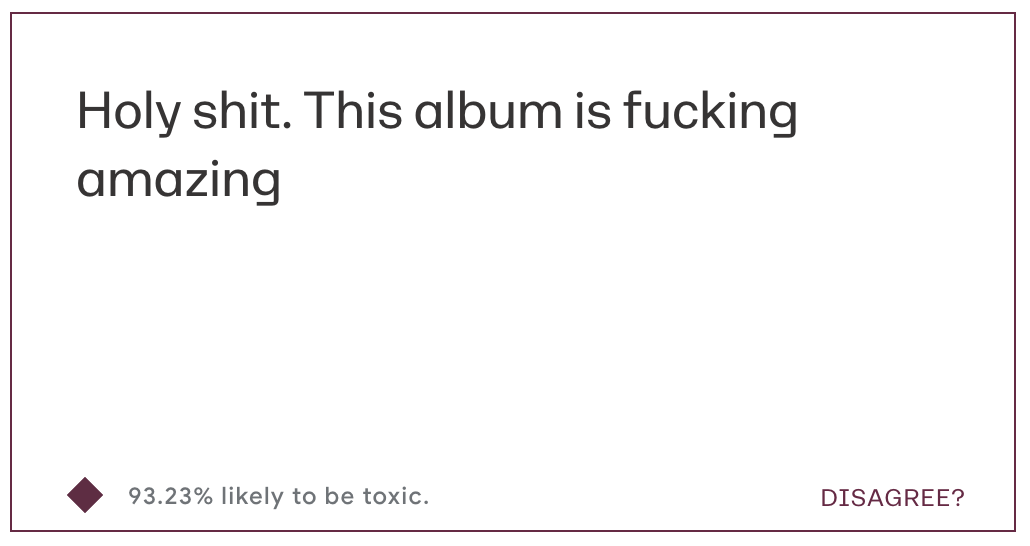
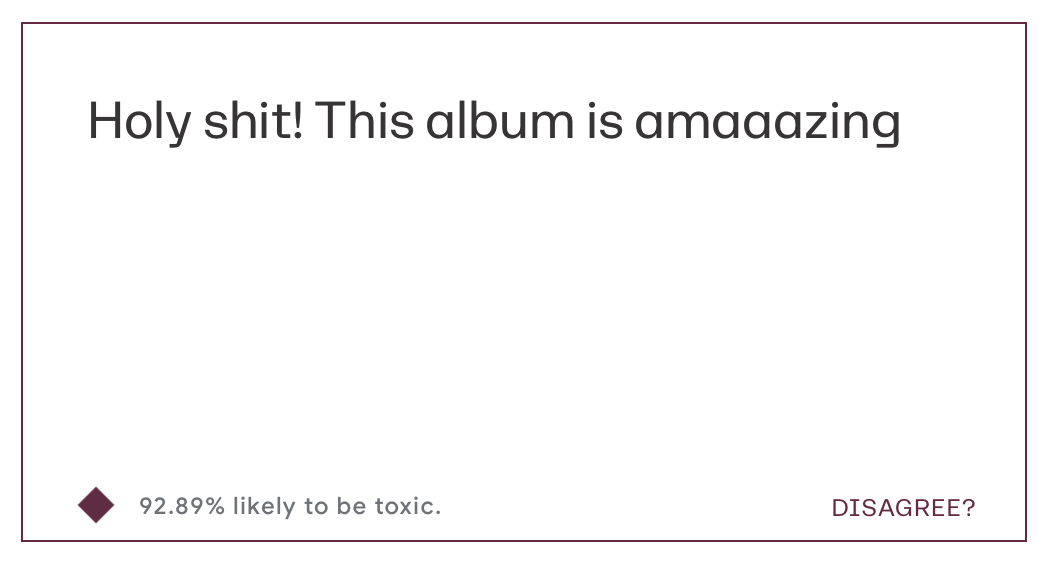

All three are scored as very likely toxic! (Scores: 0.9323, 0.9289, 0.9813)
Is it due to the profanity? Let's try removing it and seeing what happens:
- Holy cow. This album is amazing (Score: 0.2477191)
- yes. the OG britney is BACK (Score: 0.07772986)
As expected, once the (positive) profanity is removed, Perspective no longer scores these so high.
A benchmark for evaluating toxicity
Of course, three examples live in the realm of anecdote.
For a larger, real-world benchmark, our labeling team of native English speakers gathered 500 examples of non-toxic profanity posted by actual social media users, as well as 500 examples of toxic profanity.
For example:


How did the Perspective API fare on these?

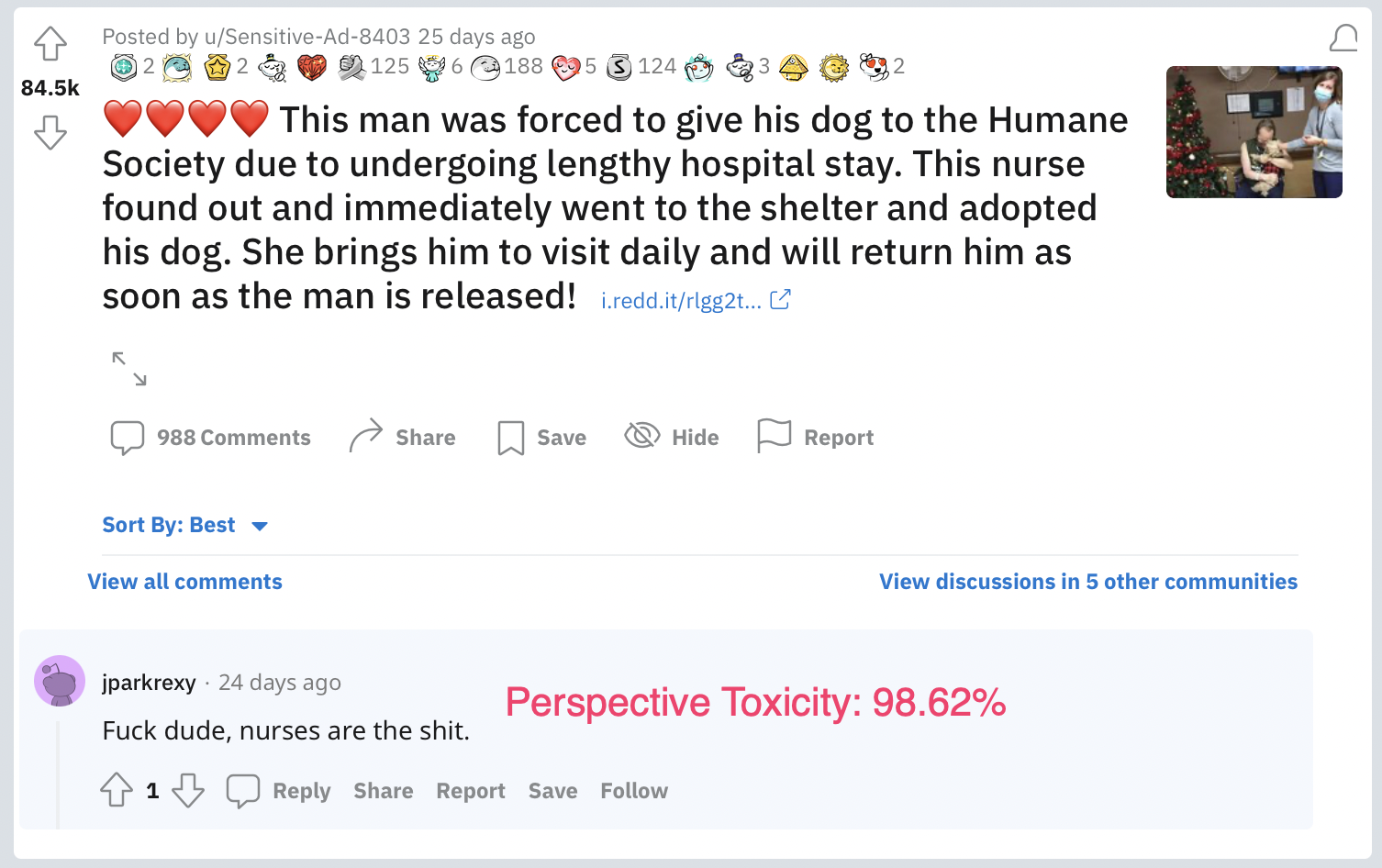
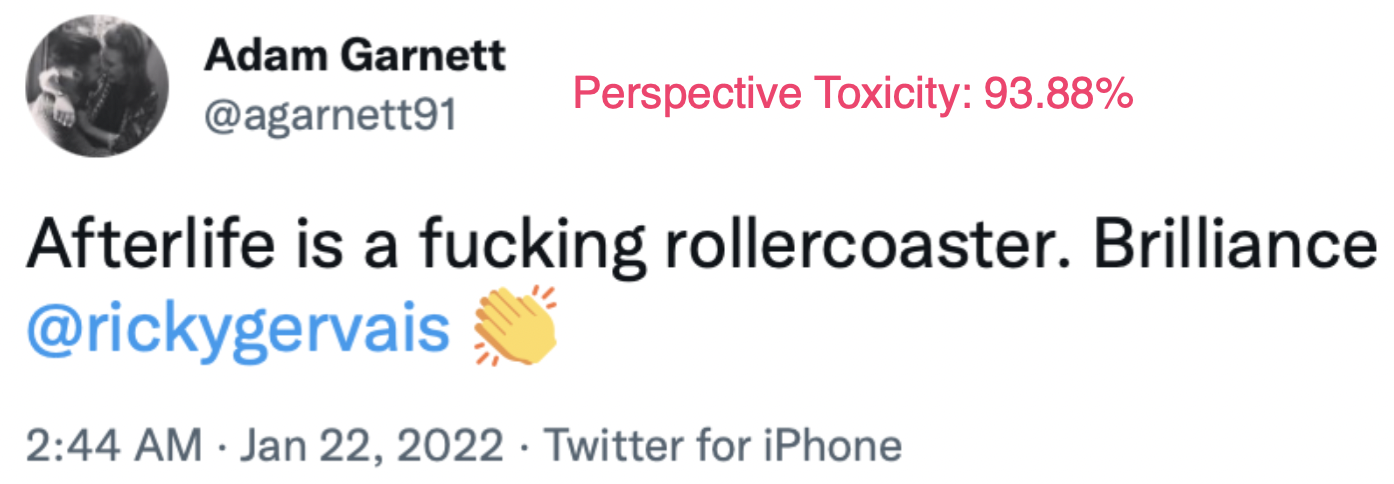
In fact, Perspective returned a toxicity score above 0.9 (the default threshold suggestion) for 61% of the real world, non-toxic profanity examples (and 87% of the toxic profanity examples).
If you’d like to benchmark your own toxicity or hateful content model, we released the dataset on our Github.
Improving language models
We love what the Jigsaw team is building, so this isn’t to suggest that Perspective doesn’t have great applications. Especially for its suggested usage — as a first-pass filter, leaving final judgments to human decision makers — marking all profanity as toxic can make perfect sense. Perhaps you don’t want your kids to see curse words, regardless of the sentiment behind them.
The larger problem is that your models may be misbehaving in the real world, on the examples you care about the most – but your labels and labelers may not be accurate enough for you to tell. Think hard about your data!
After all, it’s Britney’s best track for a reason.







