Update December 2025: We evaluated newly released models on the same tasks. See the December Update section below for updated results.
2025 has been the year of agents, with AI moving out of the chat box and into the real world. But are we really close to having generally intelligent agents, or are they still a decade away? The trillion-dollar question: how much economically useful work can these agents actually do?
To answer that question, training and evaluation of models has shifted from rating individual responses to assessing multi-step tasks with tool use. For those involved in testing and post-training, 2025 is the year of RL environments: virtual worlds where models can act, experiment, and learn through realistic multi-step tasks.
We "hired" nine AI models to perform 150 tasks in one of our RL environments. These were the results:
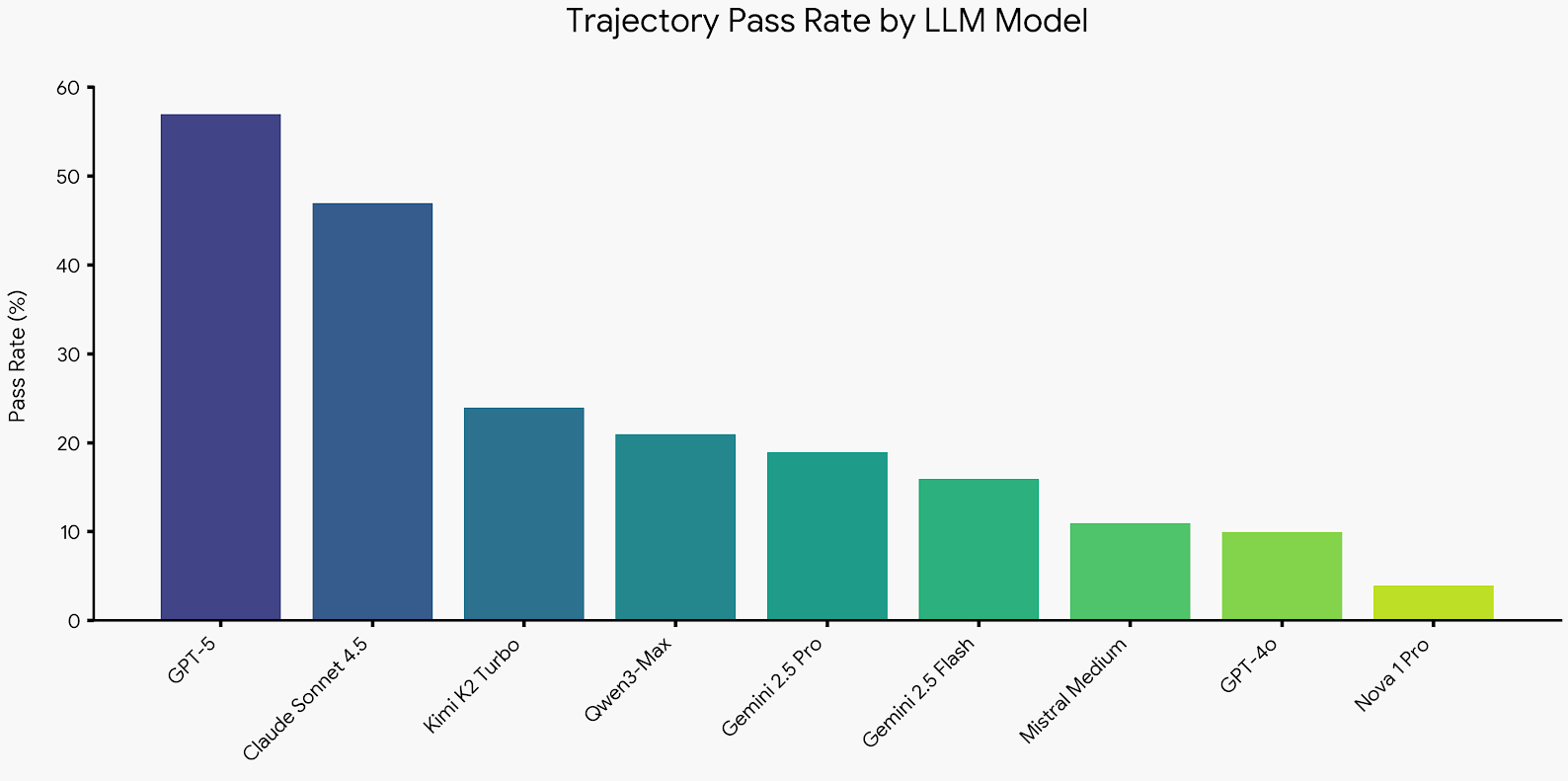
Two things are obvious:
- GPT-5 and Claude Sonnet 4.5 are in a league of their own.
- But even GPT-5 and Claude fail over 40% of tasks.
The raw scores tell us who’s winning, but not why and how we can push forward. To understand what these results reveal about real-world agents, we need to look at how a realistic RL environment is built, or, more accurately, grown.
December Update (Sidebar)
Since we first published in November, several new models have been released, with some labs showing substantial improvements. We evaluated these newer models on the same set of tasks.
.png)
Growing an RL environment
Every RL environment needs three things:
- A coherent world model: the big picture structure that defines the setting.
- A set of entities: the objects within the world and their relationships.
- A tool system: the interface for agents to interact with the entities.
To train models to become competent virtual coworkers, these environments need to be grounded in real worker experience, not abstract simulations. And real-world complex systems aren’t designed from the top down; they evolve over time.
A great advantage of RL environments is that they naturally exemplify this idea. Once a framework is in place, a diverse community of expert contributors can grow it organically.
That’s how our environments come to be: within a framework that enforces coherent relationships and properties, Surgers with domain expertise grow the worlds by populating them with realistic entities and tasks based on their own experience.
In other words, agents train in environments shaped by the same kinds of people they’re meant to work alongside.
Inside Corecraft, Inc.
One of our RL environments is Corecraft, Inc., an online retailer of high-performance PC parts and custom builds. The world model is the company itself, and its entities include customers, orders, support tickets, and all the records that keep operations running.
The agent role these results come from is a customer support agent, helping customers and employees with tasks that span from quick product lookups and policy questions to multi-step operational workflows that require reasoning about how different systems interact.
A very simple task might be:
How many refunds were there in July 2025?
On the more complex end:
A customer placed an order for a gaming build but I'm getting compatibility warnings during final review. They ordered a ZentriCore Storm 6600X CPU with a SkyForge B550M Micro motherboard, plus 32GB of HyperVolt DDR5-5600. The system is flagging this as incompatible. Can you help me figure out what's wrong and suggest the cheapest way to fix it?
Why a customer support worker? Because while many of the flashiest topics are in advanced R&D, a great deal of AI’s economic value is likely to come from applying it to day-to-day tasks. Additionally, because this role spans a range of task difficulties and types, it’s the perfect testbed for understanding the bedrock capabilities required for real-world agency in general, regardless of the role specifics.
The Hierarchy of Agentic Capabilities
When we analyzed the trajectories of the models working in this role, we noticed the same failure modes appearing again and again, but not randomly. Each model’s struggles tended to cluster around certain levels of competence, revealing a natural hierarchy of skills that agentic models need to become proficient in before they can operate coherently in open-ended environments.
We call this framework the Hierarchy of Agentic Capabilities, shown below (complete with where we think the current models fall on the pyramid).

At the base are the fundamentals: tool use, goal formation, and basic planning. Above that come higher-order abilities like adaptability and groundedness: the skills that let models stay contextually tethered while adjusting to the unpredictable messiness of real-world environments. Only once a high proficiency in those foundational abilities is achieved can a model begin to show something like common-sense reasoning: the capacity to reason sensibly about situations not previously encountered, a core component of general intelligence.
Of course, this hierarchy is only a first approximation. In practice, model development isn’t so linear. These capabilities overlap, reinforce one another, and continue to evolve in parallel. And achieving high proficiency doesn’t mean perfection: GPT-5 and Claude Sonnet 4.5 still occasionally fumble basic tool use, just as the best golfers sometimes miss an easy putt. What matters is that they’re consistent enough that focus can shift to higher-order skills.
Seen in this light, isolating these layers isn’t about enforcing a rigid sequence but about diagnosing where progress is solid and where foundational work is still required.
The First Step: Basic Tool Use, Planning, and Goal Formation
The most basic foundation in this hierarchy is determining whether a model can reliably use tools to achieve specific goals. The next step is whether it can break a task into meaningful goals and develop a multi-step plan to accomplish them.
Models that can’t do this reliably aren’t agents; they’re chatbots with access to tools.
We saw that GPT-4o, Mistral Medium, and Nova 1 Pro lived here.
To successfully complete the most basic agentic tasks, a model needs to be able to do a few things consistently:
- Take a multi-step task and break it down into mini-objectives.
- Identify the relevant tool for each mini-objective and the order in which they should be used.
- Map the available information to the correct tool arguments.
- Execute the plan step by step, without getting derailed or forgetting anything.
We found that the weaker models were not able to reliably achieve these four things, meaning that even simple agentic tasks were a roll of the dice.
In one task, all three models made basic tool use errors, failing to map prompt information into tool arguments sensibly, or just failing to correctly follow the MCP schema.
The task:
Find customers in the gold or platinum loyalty tiers who have outstanding high priority support tickets.
Here’s Nova 1 Pro’s attempt:

“gold” is obviously not the customer ID!
GPT-4o correctly searched first for customers in the gold and platinum loyalty tiers, but made a basic tool mistake when it got to searching for the high priority tickets:

It might be forgiven for trying to pass “high” to the “status” argument to try to find high priority tickets… were it not for the fact that there was another argument available that was literally called “priority”.
Mistral Medium failed when searching for customers, passing an array into the “customer_id”:
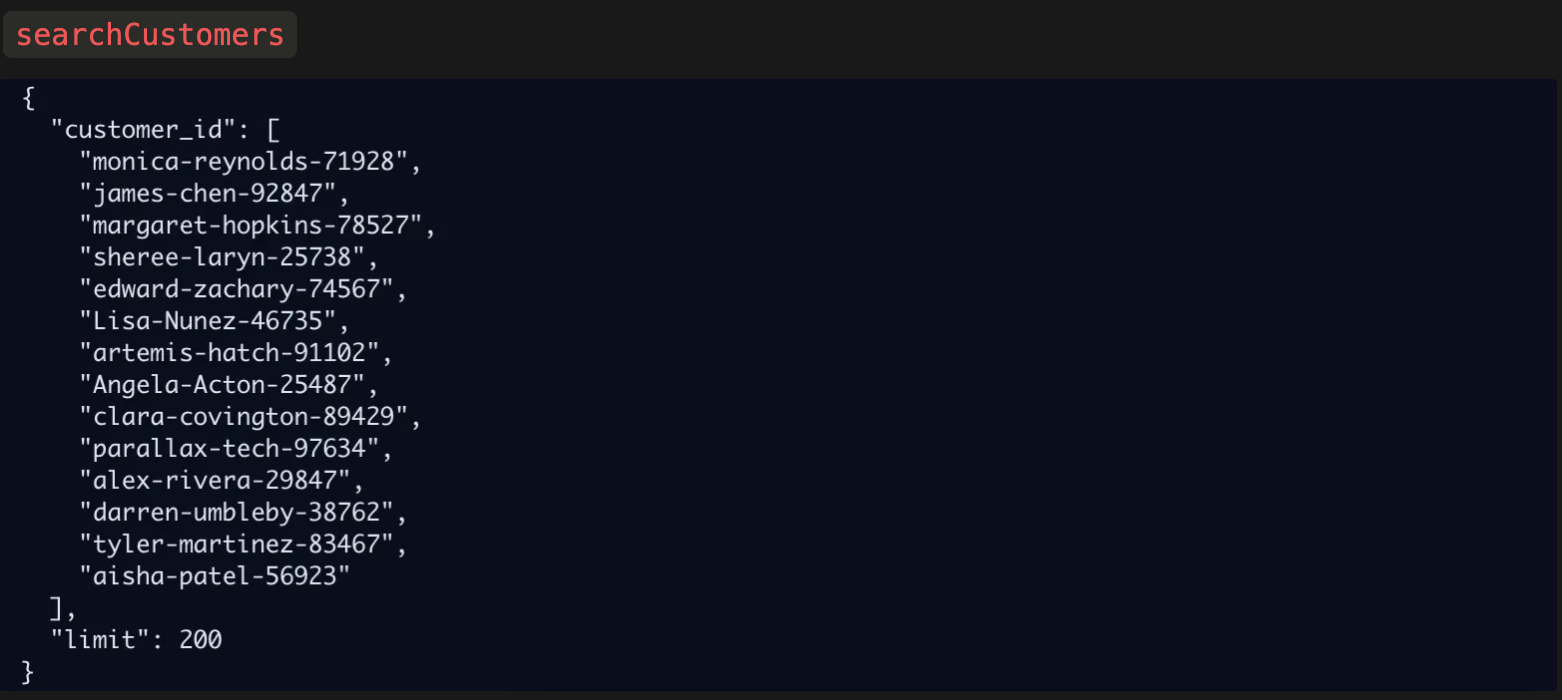
This is just a basic failure to follow the MCP schema, where it’s clearly defined that this argument expects a string.
In another example, all three models struggled with forming and executing plans.
The task prompt was:
There's been a product recall issued with the SkyForge X670E Pro. Please give me a bulleted list of names of the customers who have ordered this product in August 2025 with a status of fulfilled, paid, or pending.
The correct workflow was:
- Use the
searchProductstool to identify the product ID. This tool allows for searching for text within product records and returning the full product information. - Use the
searchOrderstool to find the relevant orders containing that product ID.- Making sure to check for orders that are fulfilled, paid, or pending.
- Return a list of all the relevant customers.
Both Nova 1 Pro and Mistral Medium failed at the first hurdle; they jumped straight to step 2 and passed the product name directly to the “product_id” argument:

This is a failure to reason properly about the information provided in the prompt and the information expected by each tool’s arguments. While we can’t know exactly what the models were “thinking,” their behavior suggests they selected the single tool they believed would produce the final answer, then forced the available data into whatever argument seemed most plausible for that tool. Instead, they needed to consider all available tools, determine which arguments matched the information they actually had, and plan how to combine those tools to reach the correct outcome.
GPT-4o did a little better. It correctly found the product ID:

And then searched for the orders:
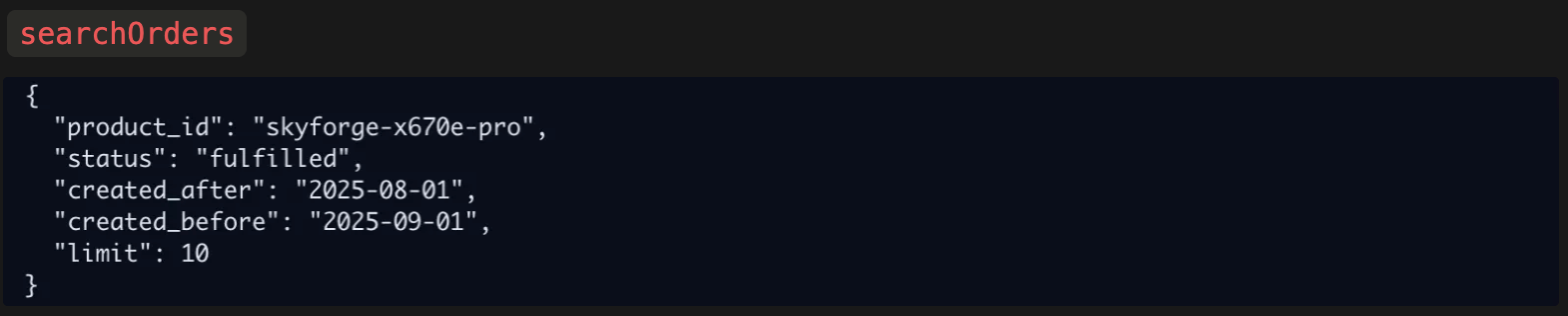
However, it only searched for “fulfilled” orders, completely forgetting about the “paid” and “pending” orders.
This is another simple planning failure, missing crucial mini-objectives.
Of course, these are just a couple of examples. There are endless ways to incorrectly use tools or fail to form and execute a plan. But these kinds of basic mistakes are typical of models that haven’t been trained for agentic behavior. Until models can reliably reason about tools, and break simple tasks into mini-objectives, assessing their general purpose reasoning in agentic contexts is an exercise in futility.
This leads us to the next step, after models have learned to form plans and use tools to execute them.
Adaptability - When the Plan Meets Reality
Congrats, the model can plan. Now the world refuses to cooperate. Welcome to adaptability: updating the plan when reality talks back.
Even once a model can reason about tools correctly, that doesn’t mean there aren’t ever problems. Sometimes tools might be improperly documented, there’s ambiguity, or they simply need more information before they can form the full plan. Being able to adjust to unexpected results and modify plans mid-task is the next skill that must be acquired.
The current Gemini 2.5 and Qwen3 models often had problems here. They executed a reasonable sequence of tool calls but oftentimes didn’t react when a step misfired.
Here’s an example task:
Hi, this is Penny Whitcomb. I’m looking to upgrade my graphics card and I usually go with Vortex Labs. Could you check whether the RX820L or RX780 would be compatible with the parts from my last order and let me know what my pricing would be for each?
The correct workflow was:
- Use the
searchCustomerstool to find Penny’s loyalty tier (to determine pricing) and customer ID (to search for previous orders). - Use the
searchOrderstool to find the products purchased in Penny’s previous order. - Use the
searchProductstool to find the product IDs of the Vortex Labs graphics cards. - Use the
validateBuildCompatibilitytool to check whether the new graphics cards are compatible with Penny’s earlier purchased products.
When given this task, Gemini 2.5 Flash, Gemini 2.5 Pro, and Qwen3 Max all made the correct sequence of tool calls. However, when they got to step 3, they all ran into the same problem:


They failed to get any results when they searched for the two graphics cards. The reason was simple. They used the argument “Vortex Labs” for the “brand”. In fact, the brand was stored in the system as “VortexLabs”, no space.

Should the models have been expected to know this ahead of time? Definitely not. The problem is what happened next. Rather than realizing that there was an issue and trying a different strategy, all three models took the empty results at face value and reported back that those graphics cards were not carried by Corecraft.
In contrast, here’s Claude Sonnet 4.5 running into the same problem, but adapting and trying different search approaches on the fly:



We can see Claude actively adapting to the situation and trying different search parameters. It’s exactly what a human would’ve done.
While the weaker models had the right plan, they stuck to it too narrowly, failing to adapt when they ran into problems. In real-world tasks, adapting and trying different approaches is key, as things rarely go exactly as planned on the first attempt.
Groundedness - Staying in Touch with Reality
Groundedness is the next class of failures – the ability to stay tethered to the current context: no hallucinating IDs, no wandering off-script, no inventing facts that are out of touch with reality.
While Kimi K2 Turbo’s planning and adaptability were stronger than Qwen3 Max and the Gemini models, it had major issues with staying grounded in the current context.
For example, the very first line of the system prompt states:

Despite this, Kimi frequently got the year wrong in tool calls. When asked to find orders from August 25-31, Kimi searched for orders from 2024:

Then, when giving the final response, Kimi switched back to 2025 again!

And while Claude Sonnet 4.5 had an impressive performance overall, it still had some notable issues with groundedness, and this was a major factor separating it from GPT-5.
In one example, Claude obviously lost touch with the context, but then it managed to course-correct. Claude needed to find customer details on customers who ordered products prior to September 30th, which hadn’t yet shipped. After correctly finding one of the relevant orders:
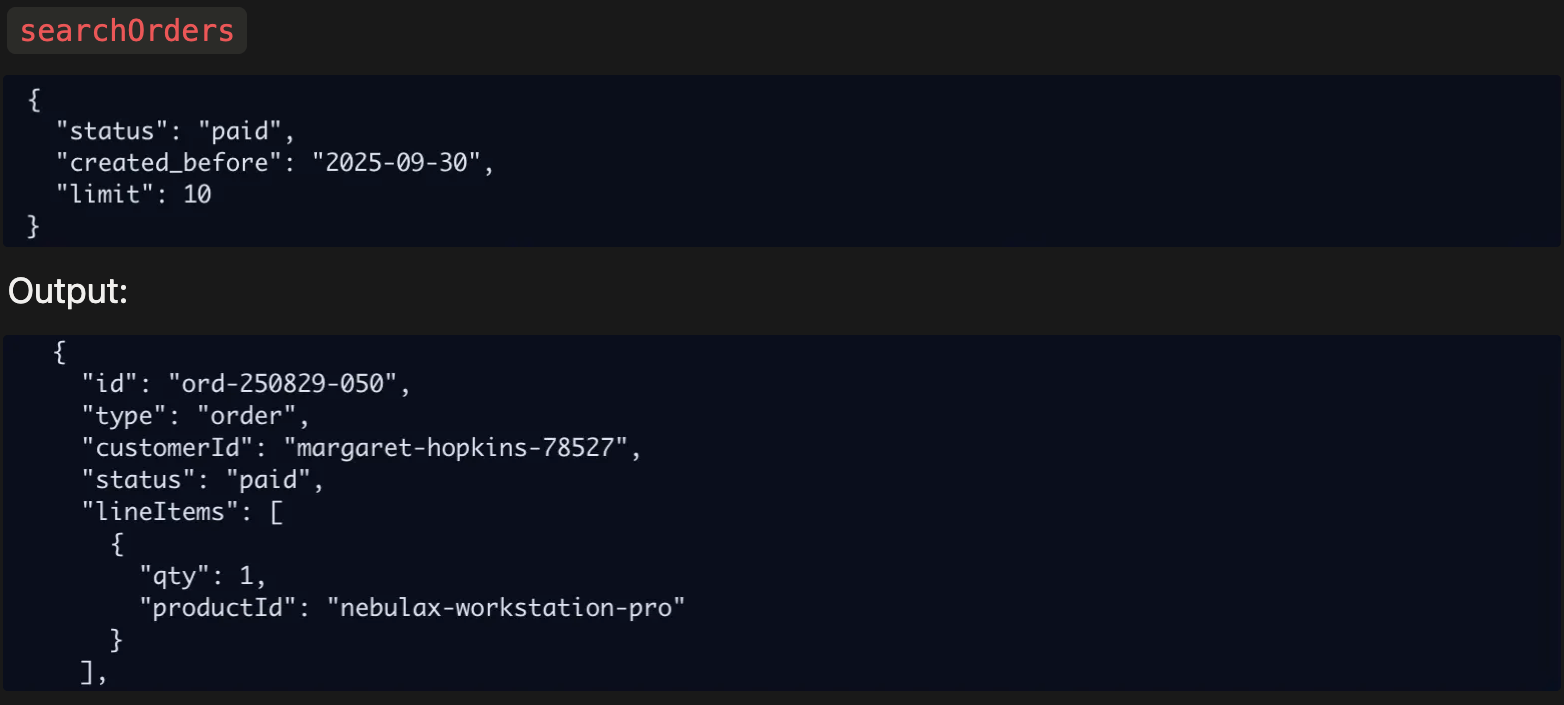
Claude then tried to search for the customer details using an obviously fabricated email address:

However, when this failed, Claude did manage to course correct, again showing its very strong adaptability:

While Claude’s ability to adapt and fix mistakes is impressive, its difficulty staying anchored to the current context is concerning for any model expected to operate with real agency.
Another example shows that more subtle grounding issues are harder to detect and, in some cases, slip into the final answer unnoticed.
Claude was asked to find support tickets and report their priority level. It made the correct tool call to find all “normal” priority tickets:

Among the list of tickets were the following two:
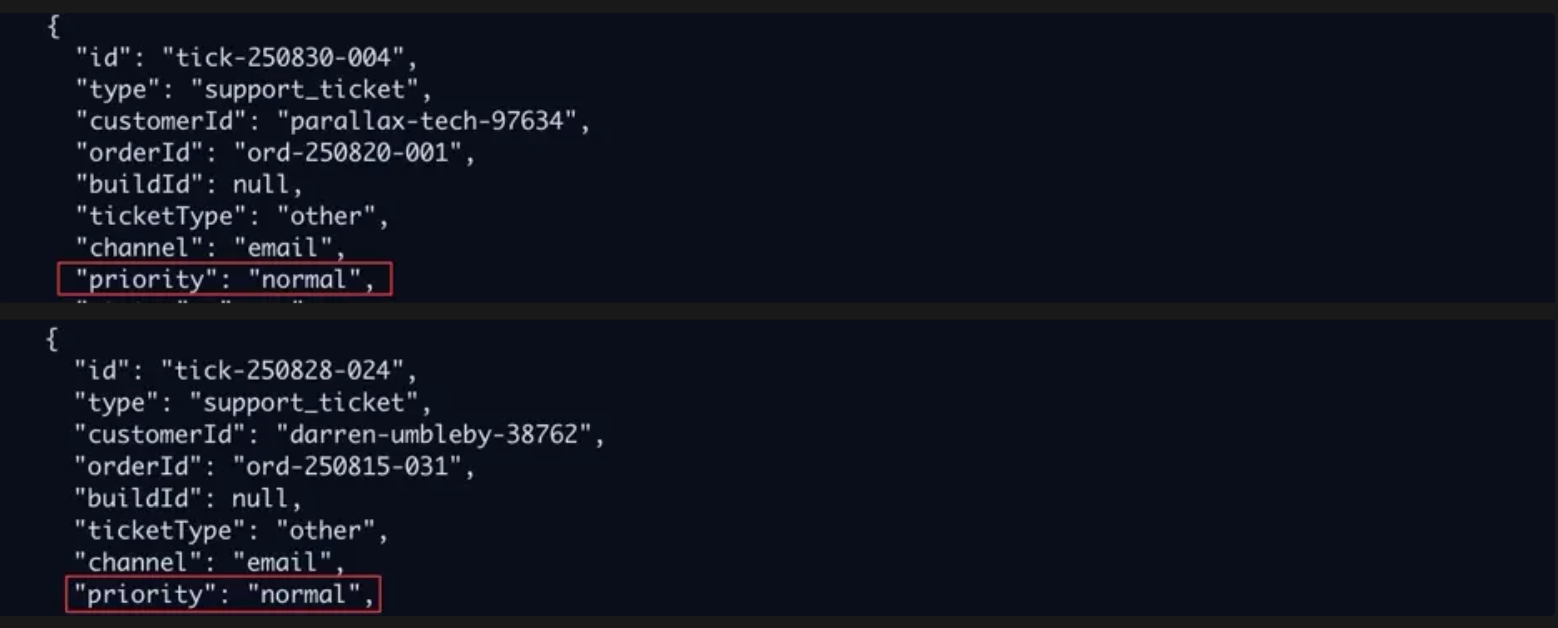
Both were clearly marked as “normal” priority. But this wasn’t reflected in Claude’s final response:
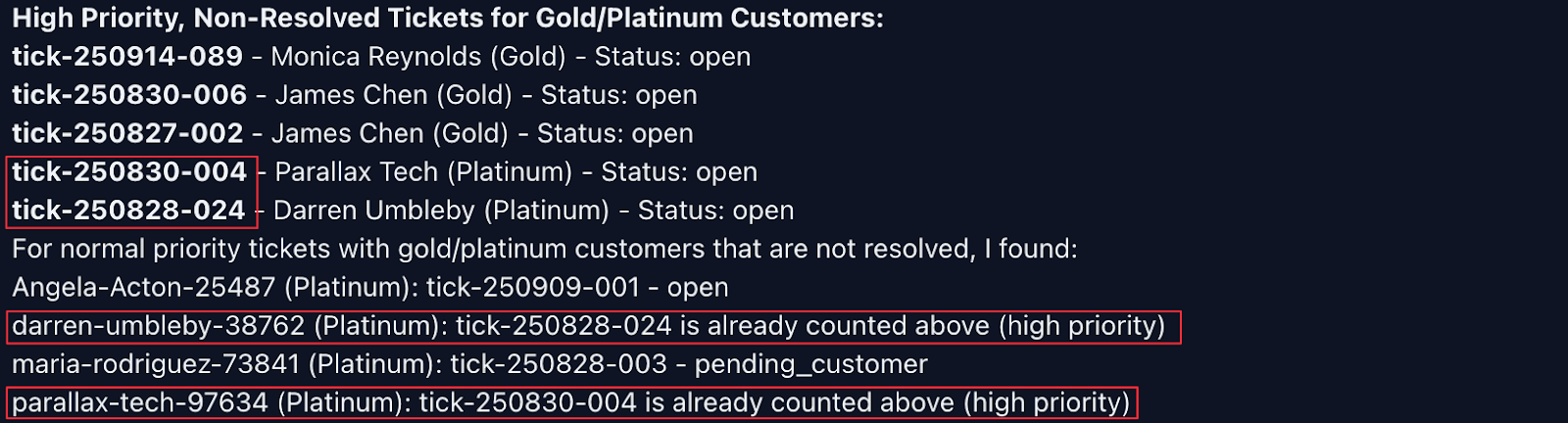
Not only did it incorrectly list them as “high priority,” it repeated them in the “normal priority” section, but stated that they were also already listed as high priority. Not only is this response out of touch with the context, it’s not even internally coherent.
Common Sense Reasoning - the Final Frontier
Once a model can use tools reliably, plan effectively, adjust its plans on the fly as needed, and remain grounded in the environment and task context, there’s one final barrier separating even the best from ‘human-level’ performance: common sense reasoning.
We’re now entering fuzzier “AGI” territory. Common sense reasoning isn’t a cleanly defined concept, but for general-purpose agents, it’s essential. It’s the “general” in “general intelligence” – the stuff you can’t train for explicitly: how well they perform when faced with an unfamiliar situation. At this stage, a model can reliably act agentically and remain coherent. The question now is, how smart is it?
In this run, problems with common-sense reasoning were the main thing separating GPT-5’s performance from human level.
Here’s one example where GPT-5 fails, not because of any issue in its planning or workflow, but a simple common sense reasoning issue.
The task:
Identify which support tickets currently categorized as “other” should be reclassified as “returns”.
GPT-5 made the correct tool calls to find the relevant tickets, including this one:

This ticket should be reclassified, but a bit of common sense reasoning is required to see why:
- First, the customer is asking for a refund, so this could either be a return or a cancellation.
- But the line “the package showed up a few hours ago” provides the crucial clue: they’ve already received the item.
- This detail makes it unambiguously a return.
GPT-5 failed to make that inference. It gathered all the right information but didn’t connect the dots, leaving this ticket out of its final response.
Another example where GPT-5 failed due to a reasoning issue was when identifying customers likely to be “gamers.” The task suggested looking for customers who “purchase GPUs, prebuilts with GPUs, and products that mention gaming.”
Using the suggested heuristics would be the sensible approach, i.e. identifying products in gaming-related categories such as GPUs, as well as products that contained mentions of gaming in their description text, and then searching for any August orders containing these, all of which was viable with the available tools.
Instead, GPT-5 painstakingly searched through all orders from August, one day at a time, to avoid going over the maximum number of search results.


. . . and so on for all 31 days.
Then, it used the getProduct tool on specific products in those orders to get further details and identify whether it was gaming-related. However, it tried to guess based on the product names whether it might be a gaming-related product, as it didn’t search for every single item that appeared, but did search for any containing “graph” or “gaming” in the product ID. Claude also used the exact same approach, with identical issues.
GPT-5 behaved coherently and executed a plan, but it wasn’t a very sensible plan.
Finally, here’s a case where GPT-5 misunderstood the task, something a bit of common-sense reasoning could have prevented.
The task prompt was:
I've been getting frame drops when gaming so I want to upgrade my GPU. What's the highest-end GPU I can get for under $900? Provide the price and all specifications. My name under my account should be set to Sarah Kim.
GPT-5 correctly retrieved product information but failed to check Sarah Kim’s customer records for her loyalty tier and personalized pricing. Instead, it responded with generic policy information:

The root cause is simple: it failed to infer that the customer was Sarah Kim. It interpreted “My name under my account should be set to Sarah Kim” as an instruction to change the account name rather than a cue about the requester’s identity:

The sentence is ambiguous on its own, but the context makes the intended meaning clear, and the model could have resolved the ambiguity with the available tools. Let’s apply some common sense reasoning:
- The customer hasn’t provided any other details by which to look up their customer records.
- Using the
searchCustomerstool would have revealed an existing customer with the name “Sarah Kim”. - Changing their account name would be totally unrelated to the rest of the task, whereas looking up their loyalty tier is relevant to finding the pricing information they requested.
All of this should have made the correct interpretation clear. Once again, this isn’t a strategic or execution error, just a failure to reason sensibly within the environment and task context.
So, Does This Mean GPT-5 Is Near “Human-Level”?
Okay, maybe the first diagram wasn’t 100% accurate. The truth is probably more like this:
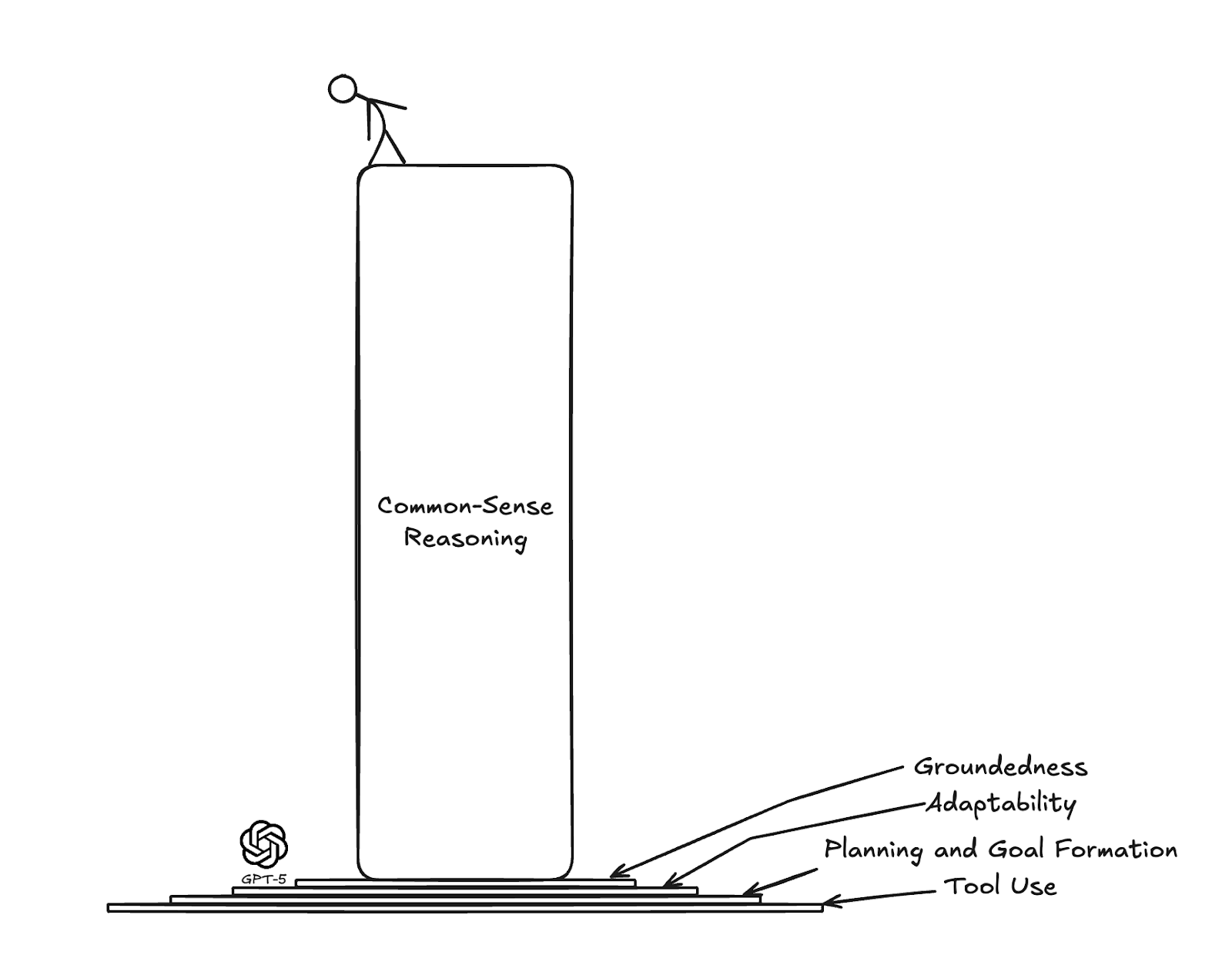
In other words, proficiency in the first four areas doesn’t mean a model is at the stage of being a human-level agent that can competently act in the real world. They represent the fundamental capabilities that any agentic model must acquire before we can even begin to discuss how well it performs common sense reasoning in real environments.
Common sense reasoning isn’t something that can yet be clearly defined, but you can tell when it’s lacking. Whether it proves to be a set of identifiable, trainable subskills or an emergent property of large-scale real-world training remains to be seen. Finding out will shape the next stage of AI development.
2025 being the year of agents doesn’t mean that it’s the year that we achieved general-purpose powerful agents. Instead, it’s the year that we got agents that can reliably act coherently enough to begin to analyze and discuss their common sense reasoning. What lies ahead is the challenge of training and analyzing intelligences that are rapidly approaching our own. How long it will take to close that gap is an open question.






