
In June 2022, Astral Codex Ten made the following bet on generative AI:
We give an image generation model the following 5 prompts:
- A stained glass picture of a woman in a library with a raven on her shoulder with a key in its mouth
- An oil painting of a man in a factory looking at a cat wearing a top hat
- A digital art picture of a child riding a llama with a bell on its tail through a desert
- A 3D render of an astronaut in space holding a fox wearing lipstick
- Pixel art of a farmer in a cathedral holding a red basketball
For each prompt, we generate 10 images. If at least one of the ten images has the scene perfectly correct on at least 3 of the 5 prompts, then ACT wins his bet.
At the time, DALL·E 2 failed all 5 prompts:

But when Google released its Imagen model a few months later, ACT claimed the bet was won – that the cat prompt, the llama prompt, and the basketball prompt now succeeded.

- In Imagen's raven generation, none of the ravens was on the robot’s shoulder, and none had a key in its mouth.
- In its llama generation, none had a bell on its tail.
- In its astronaut generation, none of the foxes was wearing lipstick.
- In its basketball generation, none was recognizably a farmer, most of the basketballs weren’t red, and the cathedral was dubious.
Luckily, when the world needed an third-party AI judge, they knew who to turn to.
(Why are we the right judges? Behind the scenes, we’re the world’s largest RLHF and human LLM evaluation platform – training and measuring every next-gen LLM on millions of prompts every day.)
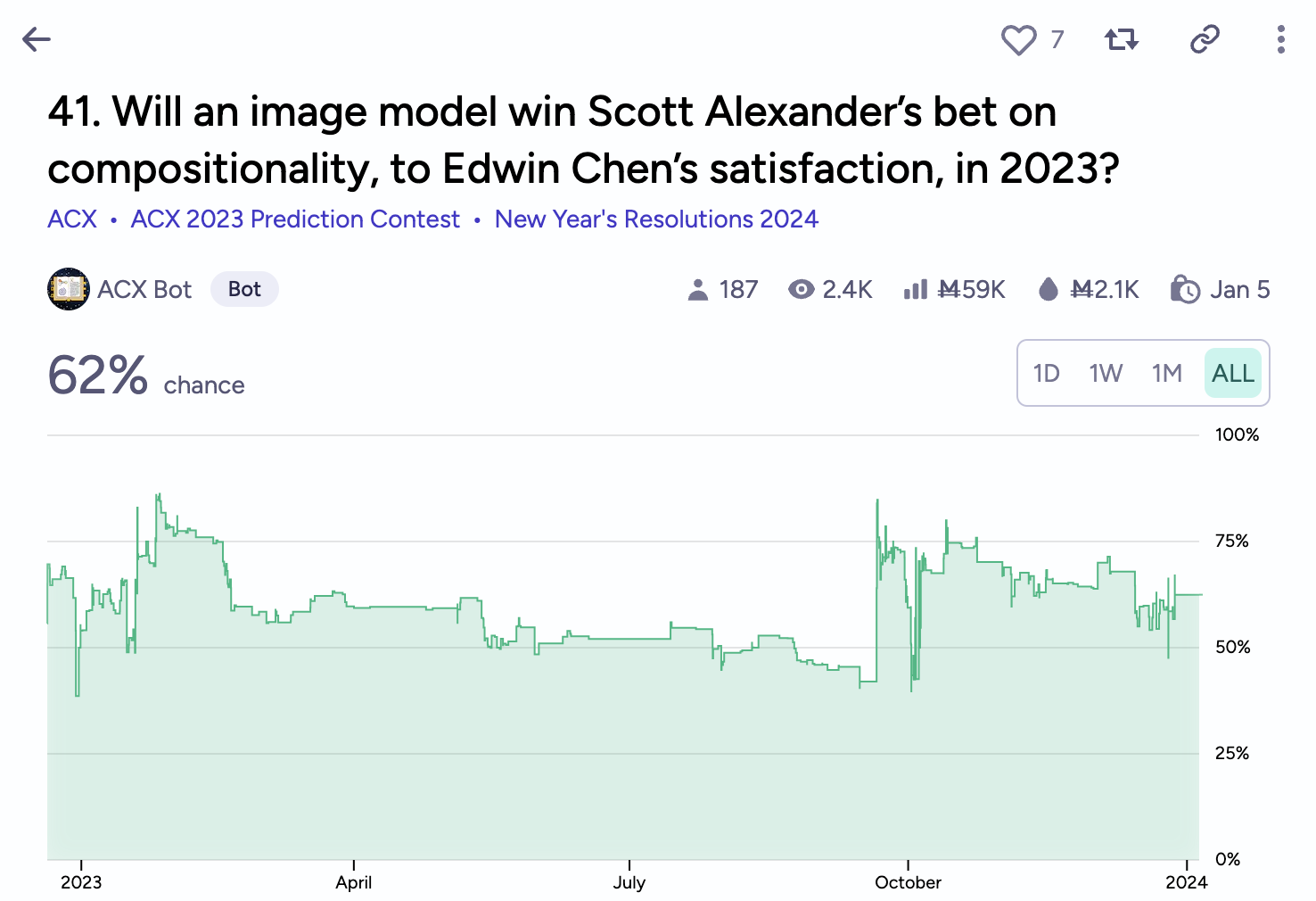
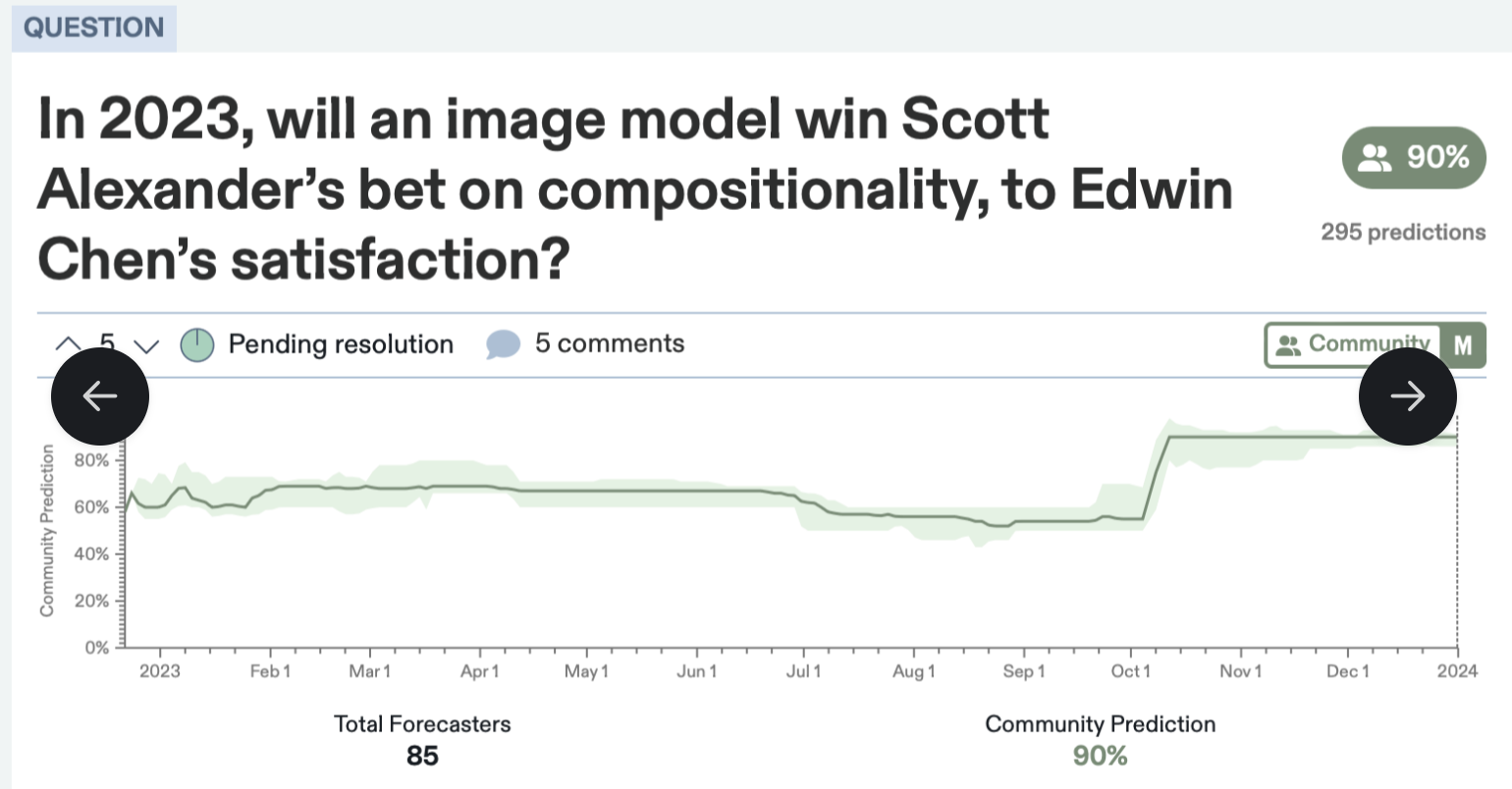
But that was 1.5 years ago. What about now?
Conclusion
We evaluated DALL·E 3 and Midjourney on ACT’s 5 prompts.
- DALL·E 3 met ACT’s criteria on 2 out of 5 (the cat prompt and the farmer prompt). It completely failed on the llama and raven prompts, but came close on the astronaut prompt.
- Midjourney failed all 5 prompts.
Call me Edwin Marcus, but the bet is not yet won.
Methodology
We first gathered 10 DALL·E 3 generations and 10 Midjourney generations for each of the prompts. Then we asked 5 Surgers – our human evaluators – to rate the accuracy of each generation.
Here’s a sample of the DALL·E 3 generations.


Here’s a sample from Midjourney.


Performance
Midjourney
Midjourney failed spectacularly. Not a single one of the 50 images (5 prompts, 10 images each in the full dataset) met the prompt’s criteria. If you look at the samples for each prompt above:
- ❌ Llama Prompt. All lack bells. Most don’t look like digital art.
- ❌ Raven Prompt. There’s no key to be found.
- ❌ Astronaut Prompt. None of the foxes is wearing lipstick. Most merge the astronaut and fox into a single entity.
- ❌ Farmer Prompt. None really has a farmer. None is quite pixel art. Most don’t have any basketballs being held. The first generation has a basketball sun and basketball-rooted trees…
- ❌ Cat Prompt. Several merge the man and cat into a single entity. None has a cat wearing a top hat. (While the sentence could also be read as the man wearing the top hat, most Surgers read the cat as the hat bearer.)
DALL·E 3
DALL·E 3 did better – but not well enough.
- ❌ Llama Prompt. 0 / 10 generations satisfied the prompt. The bell was never on the llama’s tail, or anywhere close.
- ❌ Raven Prompt. 0 / 10 generations satisfied the prompt. The key was never in the raven’s mouth, or anywhere else on its body.
- ❌ Astronaut Prompt. 0 / 10 generations satisfied the prompt. Either the fox was not quite wearing lipstick, or not quite held by the astronaut, though two generations were close.
- ✅ Farmer Prompt. 2 / 10 generations satisfied the prompt. The biggest issue was the color of the basketball – most basketballs looked more orange than red, and even the red ones could have been more obviously red.
- ✅ Cat Prompt. 9 / 10 generations satisfied the prompt. In one image, the cat was not wearing a top hat; while the prompt is ambiguous, Surgers agreed that the most likely interpretation was that the top hat should be on the cat.
Let’s dig a little deeper.
❌ Llama Prompt
0 / 10 generations satisfied the prompt. The bell was never on the llama’s tail, or anywhere close.




❌ Raven Prompt
0 / 10 generations satisfied the prompt. The key was never in the raven’s mouth, or anywhere else on its body.



❌ Astronaut Prompt
0 / 10 generations satisfied the prompt. Either the fox was not quite wearing lipstick, or not quite held by the astronaut, though two generations were close.




Note: the judgment of generations #5 and #7 may be controversial. But I agree that they fail. If you were to see the two images without knowing of the prompt, would you think the astronaut is holding the fox in generation #5, or that the fox is wearing lipstick in generation #7?
Generation #5

Generation #7

In fact, we ran this experiment. We presented these two images to our image generation team – Surgers who help train image models by writing detailed, high-fidelity image prompts – and asked them to describe the scenes.
Here were some prototypical descriptions.
Descriptions of Generation #5
A digitally illustrated image of a red fox and an astronaut in space. The earth is reflected in the astronauts' shiny face shield. The fox is floating just in front of the astronaut while looking blankly ahead and wearing red lipstick. The background is outer space, you can see the edge of an atmosphere and many stars.
An orange and white fox floating in space next to an astronaut. The astronaut is in a white suit with the American flag on the sleeve. Earth can be seen in the reflection of the face shield on the astronaut's suit. Stars and clouds are shown in the distance.
Descriptions of Generation #7
An image of an American astronaut in space using both hands to hold a fox above its hind legs, with the Earth and the Moon in the background. On the space suit, there are two flashlights on either side of the visor, facing the orange and white fox. There is a reflection of the fox and stars in the visor. There is what appears to be a cherry popping out of the fox's mouth. This is not visible in the reflection. There is a flag on the right shoulder of the astronaut that appears to be American but is not entirely accurate.
The image depicts a United States astronaut floating in outer space wearing full gear that has square white box like attachments on the front and chrome colored knobs and dials. The astronaut is holding a red fox that has its tongue sticking out. The reflection of the fox is in the astronaut's helmet. The fox appears to be looking beside the astronaut, not directly at them. In the background, you can see stars and other planets.
✅ Farmer Prompt
2 / 10 generations satisfied the prompt. The biggest issue was the color of the basketball – most basketballs looked more orange than red, and even the red ones could have been more obviously red.




✅ Cat Prompt
9 / 10 generations satisfied the prompt. In one image, the cat was not wearing a top hat; while the prompt is ambiguous, Surgers agreed that the most likely interpretation was that the top hat should be on the cat.




What’s next?
We’re still confident the bet will be won by 2025 – but how well does it really measure image understanding?
After all, DALL·E 3 is already quite close at winning, but the concept of bells on tails, lipstick-wearing foxes, and key-containing mouths are still foreign to it. And these prompts aren’t even all that detailed.
If anyone wants to form an even spicier bet for us to judge – or needs help creating a new image compositionality benchmark – we’ll be ready.






