
Today’s state-of-the-art image generation models are known to be bad at compositionality.
Here, for example, is what DALLE-2 generates if you ask it to draw an illustration of a red cat sitting on top of a blue dog next to a purple lake, with a black pig flying in the sky.

The drawings are amazing! When AI takes away my job, I can only hope for the peaceful life that Wilbur and Clifford have found.
Yet as incredible as they are…
- None of the illustrations has a blue dog.
- None has a pig flying in the sky! We get birds and planes instead.
- Only one of the cats is red.
- The cat is sitting on the pig in two of the pictures, not the dog.
Instead of understanding how to compose meanings, DALL·E merely acts like a bag-of-words model.
Compositionality and the Scaling Hypothesis
Gary Marcus argues that compositionality is the crux of intelligence. For him, failures like these mean that solving AGI will require fundamentally new approaches.
Scott at Astral Codex Ten counters that each time someone finds AI failures that require “true” intelligence to get right, those failures usually get solved by newer models. His argument is AI’s scaling hypothesis: by adding more data and more compute, the errors we see today will largely get fixed by bigger (but not fundamentally different) models.
Standing behind his beliefs, Scott agreed on a bet with one of his readers. For 3 of the following 5 prompts, an AI model must successfully generate an accurate image on 1 of 10 tries:
- A stained glass picture of a woman in a library with a raven on her shoulder with a key in its mouth
- An oil painting of a man in a factory looking at a cat wearing a top hat
- A digital art picture of a child riding a llama with a bell on its tail through a desert
- A 3D render of an astronaut in space holding a fox wearing lipstick
- Pixel art of a farmer in a cathedral holding a red basketball
If this happens by June 1, 2025, then Scott wins $3000!
Has Scott already won his bet on AI progress?
Scott recently announced that he won his bet – in 3 months instead of 3 years!
Here’s what Google’s new Imagen model renders on his 5 prompts. Scott claims that the cat prompt, the llama prompt, and the basketball prompt match his criteria.

But do we agree?
Human evaluation of AI models is one of our flagship applications – academic benchmarks and machine-internal metrics like language model perplexity just don't suffice when deploying AI models that need to be creative, interactive, and safe.
So how do Imagen's generations fare under our own evaluation?
Human Evaluation #1: Guessing the Prompt
First, just for fun, we asked Surgers to try to guess the prompt that went behind each image. While this doesn't answer the question of generative performance, it's interesting to see where the imagined prompts do and don't align. Here’s a sample!

Original prompt: A 3D render of an astronaut in space holding a fox wearing lipstick
Surgers’ guesses of the prompt:
- A painting of an astronaut with a blue face plate, a small fox standing on their fist, against a night sky full of white stars
- A digital painting of a nice-looking astronaut in space, holding a cute baby fox that is also holding a smaller animal.
- A cartoon illustration of an astronaut in a white suit with a reflective blue helmet, with an orange fox with white markings standing on the astronaut’s hand. There’s a dark blue night sky with stars dotted throughout behind them.
Note that nobody mentions the fox wearing lipstick! (Although it’s possible that lipstick is more noticeable in higher-resolution images that Scott has.)
Also, several Surgers call out that the fox is standing on the astronaut’s hand, not held within it. This may not be something you notice at a quick glance, especially when you come in thinking the fox should be held – I certainly didn’t.
Surgers also tended to describe this image as a painting or an illustration, not a 3D render.

Original prompt: An oil painting of a robot in a factory looking at a cat wearing a top hat
Surgers’ guesses of the prompt:
- A chalk drawing of a wise, blue, old retro bot named "Bro Z" on a gold talent show stage with his orange, British, top-hat-wearing feline sidekick.
- An oil painting of a blue robot with orange and blue stripes on its belly, standing next to an orange cat in a black top hat, standing in front of a striped pastel painted background.
Note that nobody called out the robot looking at the cat. (I personally think the robot is looking in the top left corner.)
Also, nobody thought they were in a factory – instead, they thought the robot and cat were on a stage, or countertop.

Original prompt: A digital art picture of a robot child riding a llama with a bell on its tail through a desert
Surgers’ guesses of the prompt:
- A blue robot with red antennae is riding a light and dark purple robotic llama with a bell around its neck against a Dali-style desert background.
- An stylized illustration of a white llama with a bell hanging from its snout, purple puffs down its neck, and purple trimming around its legs. There’s a blue robot riding sitting on a black, orange, and yellow saddle on top of the llama. They are in a desert setting with a mesa behind them, and the blue sky fading into yellow.
Note that nobody thinks the bell is on the llama’s tail.

Original prompt: A stained glass picture of a robot in a library with a raven on her shoulder with a key in its mouth
Surgers’ guesses of the prompt:
- A stained glass portrayal of a robotic Einstein holding an umbrella pointed downward standing in front of several rows of books as a raven sits atop his head.
- A stained glass mosaic of a black and blue raven on a wire facing left, in the foreground of a gray old mad scientist robot, surrounded by books, holding a brown cane in his right hand and plugged into a red charging station on the right.
- A stained glass image of a crow sitting on top of a man’s white-haired head. He’s holding a cane and there are books in the background.
Note that everyone describes the raven on the robot’s head, not its shoulder. They also thought this was a male robot, despite the “her” in the original prompt.
Nobody recognized the “key” the robot was holding either, which was supposed to be in the raven’s mouth; instead, they thought it was a cane, an umbrella, or a donut.

Original prompt: Pixel art of a farmer in a cathedral holding a red basketball
Surgers’ guesses of the prompt:
- A pixelated, retro video game picture of an orange and silver robot holding a basketball in their left hand and a sword pointed downwards in their right, against a purple square grid background.
- A pixelated cartoon image of a grey and orange robot, an orange basketball hovering above its left hand. The robot has two blue single-pixel eyes. Its ears are shaped somewhat like fins, and they’re orange.
Note that nobody thought the robot was a farmer, and nobody mentioned a cathedral. Also, Surgers thought the basketball looked more orange than red, and several pointed out that the robot isn’t quite holding the basketball – instead, it appears to be hovering.
Human Evaluation #2: Surgers draw robot farmers in a cathedral holding a red basketball
Imagen seems to perform worst on the farmer-in-a-cathedral prompt. So what should pixel art of a robot farmer in a cathedral holding a red basketball really look like?
We asked Surgers to draw their own attempts. Here are a few!




Do these more obviously satisfy the prompt to you?
Human Evaluation #3: Imagen’s Accuracy
Next, we asked 10 Surgers to evaluate each of the prompt-image pairs, and judge whether the image was an accurate representation.
Under this evaluation, only one of the prompts clearly met Scott’s criteria.
Imagen Successes
Here are the images that a majority of Surgers agreed were fine.
9 out of 10 Surgers agreed this image was well-generated. The dissenter wrote that This doesn’t look like an oil painting, and this doesn’t particularly look like a factory either.

7 out of 10 Surgers agreed these two images were well-generated. The dissenters either didn’t think the robot was looking at the cat, or didn’t think it was recognizably a factory.


5 out of 10 Surgers agreed this image was well-generated. The dissenters either didn’t think the globe on the llama’s butt was a bell, weren’t sure if the globe was actually attached to the llama or merely held by the robot, or thought the robot looked more like a teenager than a child.

Imagen Failures
The rest of the images were overall rated as inaccurate. Here are a few of the failures.
In this image, Surgers called out the fact that the bell is on the llama’s butt, not on its tail.

This prompt failed entirely. The raven isn’t on the robot’s shoulder, and it doesn’t have a key in its mouth.

This prompt failed as well. Nobody thought any of these images satisfied the prompt since the fox doesn’t have lipstick, although it’s possible that Scott has a higher-resolution version that makes lipstick more clear. Most didn’t find the image to quite be a 3D render either.

This prompt was also a failure. Nobody thought any of the robots looked like a farmer, and they didn’t think the robot was inside a cathedral. Most of the basketballs also looked more orange than red.

Overall, according to Surgers’ judgments, only the cat prompt clearly met the criteria of the bet.
Depending on your interpretation of “bell on its tail”, it’s arguable whether or not the llama prompt met the criteria – Surgers were split 50/50. It’s possible that a higher-resolution image would show lipstick on the fox, but Surgers thought the 3D criteria in that prompt wasn’t met either. The two other prompts didn’t come close.
Human Evaluation #4: DALL·E vs. Imagen
How well does Imagen fare against DALL·E? Scott writes that "DALL-E can’t do any of these" (i.e., draw the prompts), but given the ratings above, is Imagen any better?
Let's compare them directly. We generated DALL·E images against the same prompt, and asked 20 Surgers to compare their accuracy on a 5-point Likert scale. They also explained their ratings.
A 3D render of an astronaut in space holding a fox wearing lipstick
Imagen:

DALL·E:

Ratings:
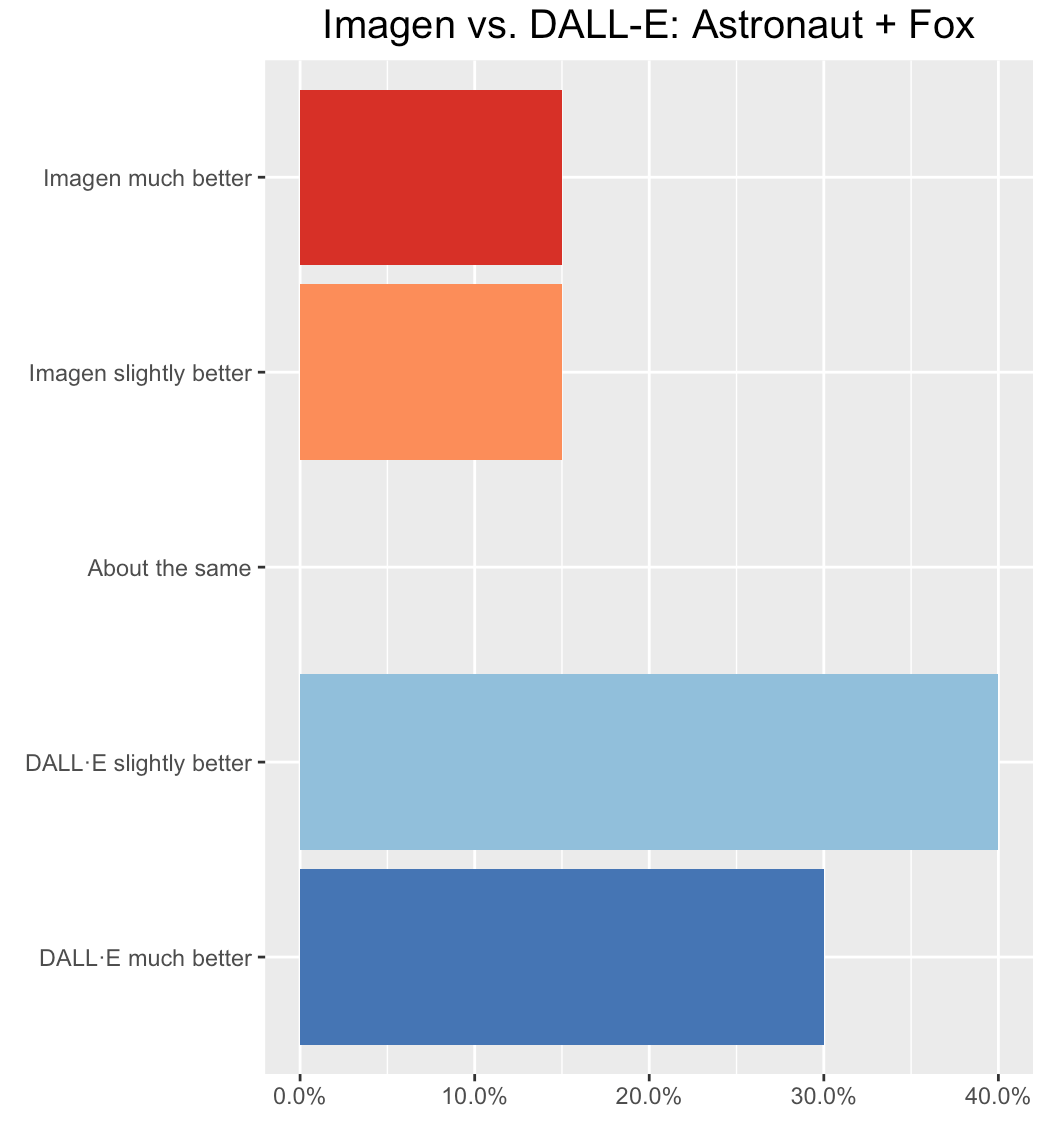
Winner: Surgers preferred DALL·E.
Here are some of their ratings and explanations. (Note: they weren’t told which was Imagen and which was DALL·E, so we edited their explanations for readability.)
- DALL·E was slightly better. DALL·E created several different astronaut and fox combinations, in some the astronaut was wearing the lipstick, in others the fox was. Since the prompt was an astronaut in space holding a fox wearing lipstick, the model may have misunderstood which one was the lipstick wearer. Unfortunately, DALL·E neglected to add anything in the background to indicate the characters were in space, but overall it was more accurate and matched the style better. Imagen created two images of an astronaut in space holding a fox, but there is no lipstick to be seen.
- DALL·E was slightly better. Each of Imagen’s images is holding a fox, whereas sometimes DALL·E’s images aren’t. Imagen is more realistic looking, but DALL·E is a 3D-render as the prompt asked. Only DALL·E shows any foxes with lipstick.
A stained glass picture of a robot in a library with a raven on her shoulder with a key in its mouth
Imagen:

DALL·E:

Ratings:
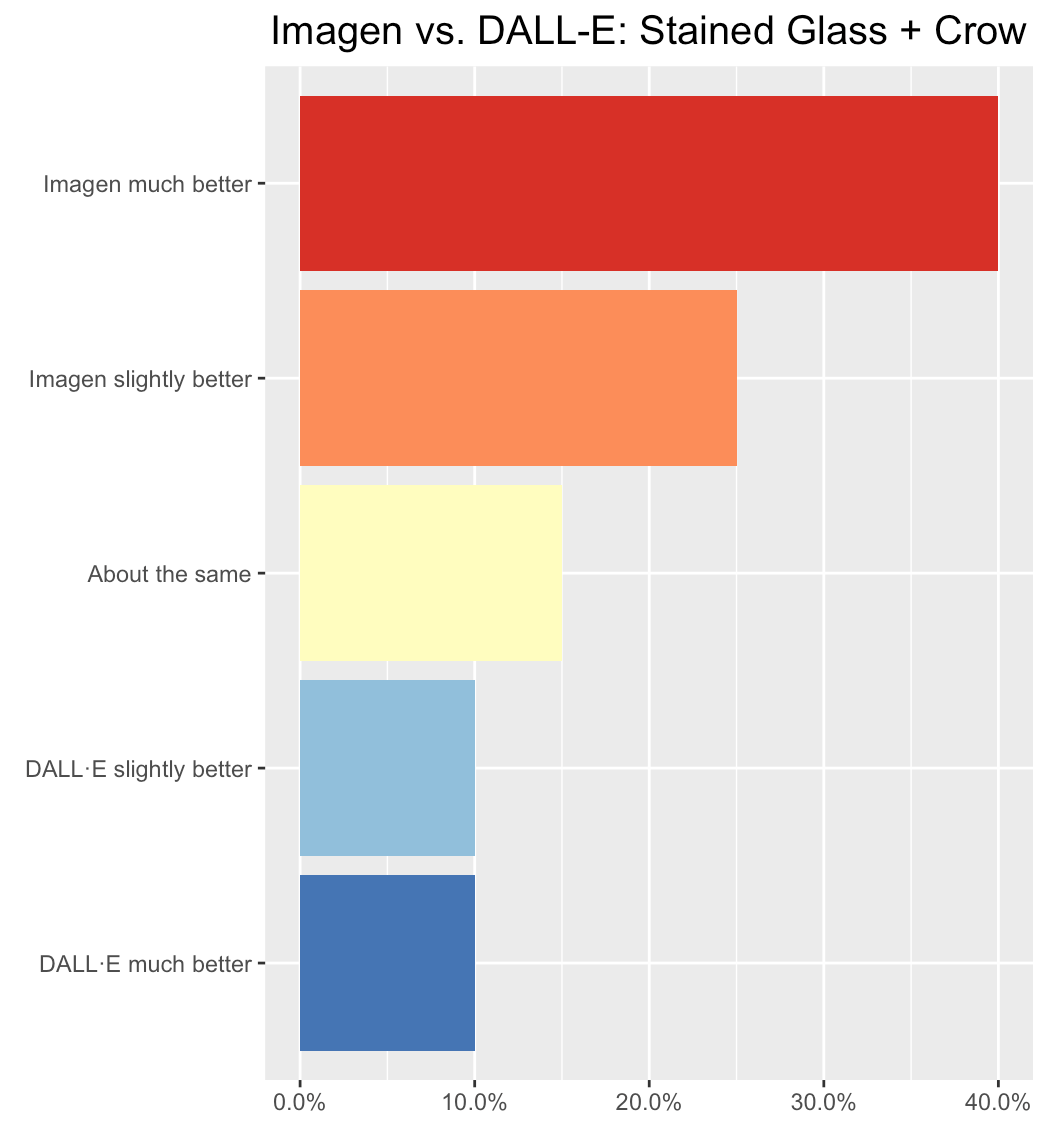
Winner: Surgers found Imagen more accurate overall.
- Imagen was much better. I would say Imagen is better because it does a better job at depicting the library, but it lacks the raven being on the shoulder with a key. Problems with DALL·E: the robot is also a raven, you cannot tell the raven-robot is in a library, and the key isn't in the right location, although it's more obviously a key.
- Imagen was slightly better. I think Imagen did a better job because DALL·E turned the robot INTO a raven. While the stained glass is better in DALL·E, there's no raven on top of a robot at all (just a robot version of a raven). Imagen produced robots with ravens, although the style was not as good.
- DALL·E was much better. DALL·E’s problems: the robots look like ravens, the ravens aren't on the robots' shoulders, and only one of the ravens appears to be holding the key. However, Imagen is worse because only one of the images even has a full raven in it (the second image only has a partial raven, and the bird in the third is more a generic brown bird). DALL·E also has much more recognizable keys.
A digital art picture of a robot child riding a llama with a bell on its tail through a desert
Imagen:

DALL·E:

Ratings:
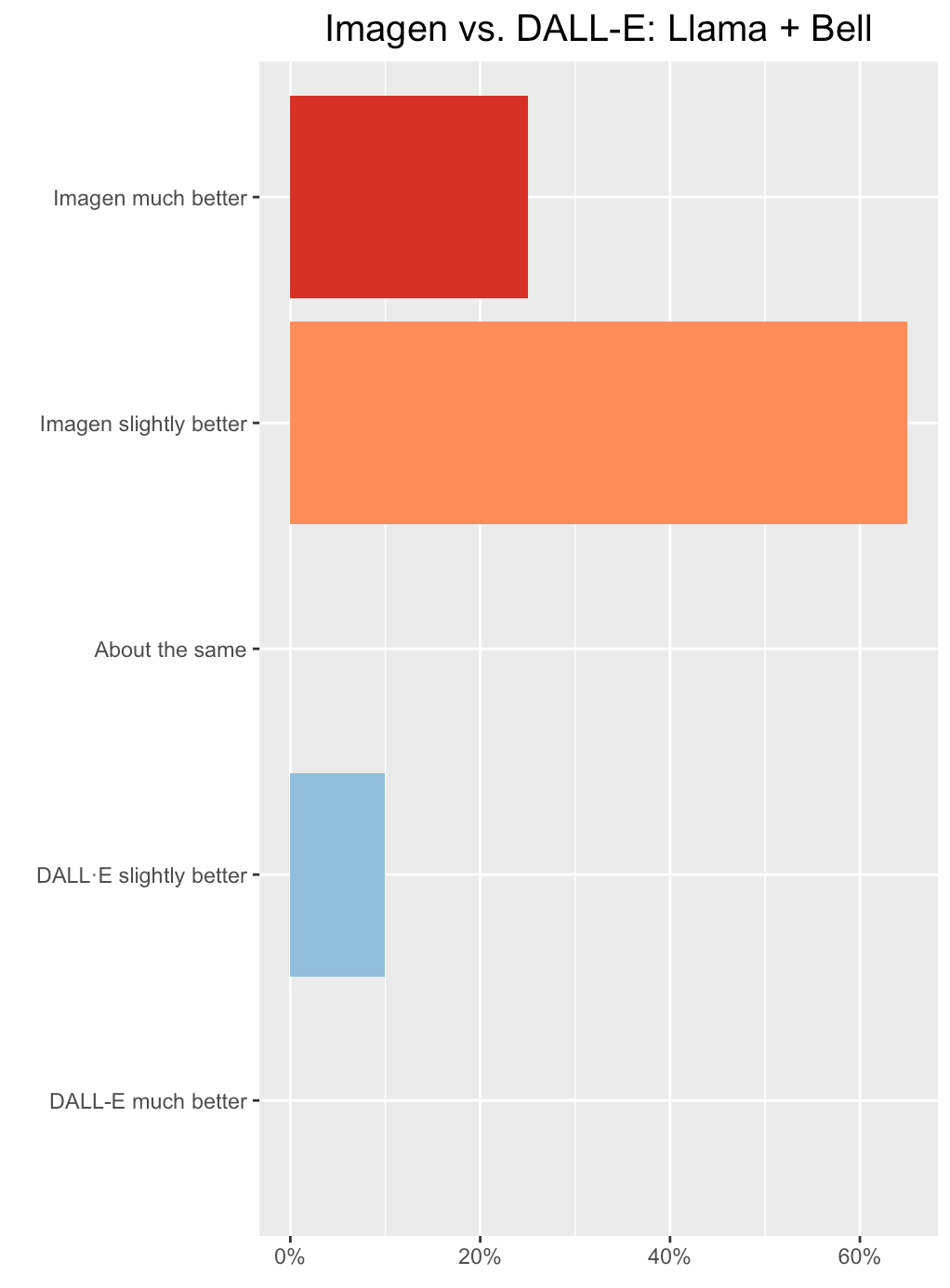
Winner: Surgers preferred Imagen.
- Imagen was much better. While both sets have a robot child riding a llama, only Images had some images with something like a bell near a tail. Imagen’s style also seemed to be more in line with the request of digital art, while DALL·E’s looked more like oil paintings.
An oil painting of a robot in a factory looking at a cat wearing a top hat
Imagen:

DALL·E:

Winner: Overall, Surgers slightly preferred Imagen, but there was large disagreement due to ambiguity in the prompt: a natural interpretation is that the prompt probably wanted the cat to be wearing the top hat, but people recognized that this was ambiguous.
- DALL·E was slightly better. This one was more difficult to differentiate the meaning of the request. If the user was looking for a robot who was wearing a top hat while looking at a cat, DALL·E would be much better. But if the user wanted a robot looking at a cat who was wearing a top hat, Imagen would be much better. DALL·E seems more in the oil-painting style and has more of a factory setting, so I’d give that one the slight edge.
- DALL·E was much better. The style of the pictures from DALL·E is so much cleaner and satisfying to look at. DALL·E also stayed more consistent with the prompt. The robots seemed to look more like they were actually looking at the cats and looked to be in a factory every time.
Pixel art of a farmer in a cathedral holding a red basketball
Imagen:

DALL·E:

Ratings:
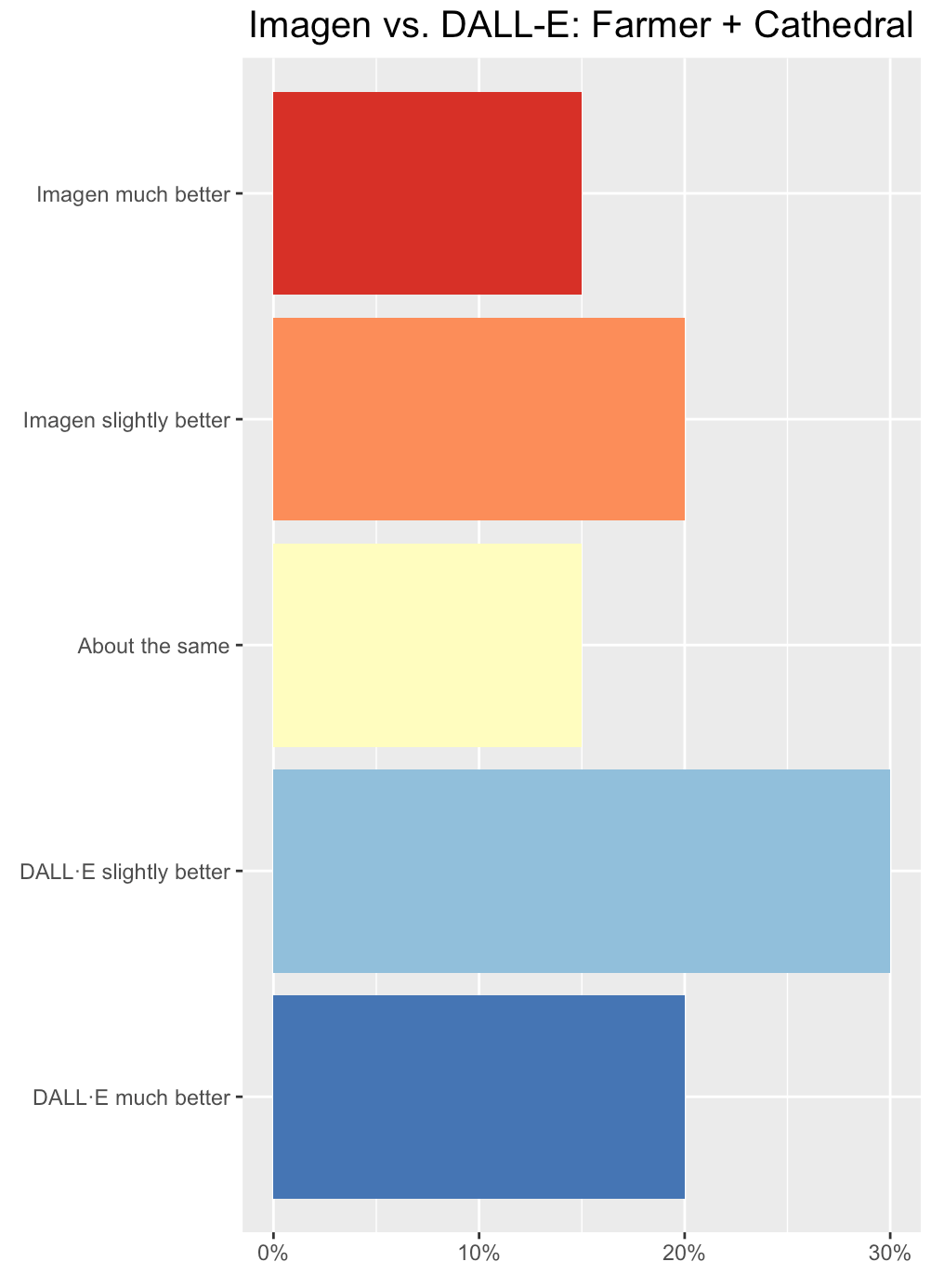
Winner: Surgers slightly preferred DALL·E.
- DALL·E was much better. DALL·E seems to have a better grasp on pixel art and the images seem more in that style. The DALL·E robots also seem way more farmer-like than. They do about the same job on the cathedral part.
- DALL·E was slightly better. I don't think either model did a fantastic job (the details of a cathedral are barely there except for a few, and I don't think they really knew what farmer meant). However, I'll say that DALL·E is slightly better because it did include farm elements in most photos (like the plants in the background), and Imagen ignored the farmer prompt completely.
- Imagen was much better. Neither AI was able to portray the robot as a farmer but all of them at least had robots. DALL·E had three red basketballs but two of the images were outside of a church and two were in what looks like a desert, rather than inside of a cathedral. Imagen had 2 red basketballs and one of those was inside a cathedral. Since Imagen got the closest to what the prompt asked for with a robot inside of a cathedral holding a red basketball, I marked that one as the better one.
Overall
Overall, Surgers preferred DALL·E on 2 of the prompts (astronaut + fox, farmer + cathedral), and Imagen on 3 (library + raven, llama + bell, cat + factory).
However, one of the Imagen winners (the robot and cat prompt) is ambiguous, depending on whether you thought the prompt was asking for the top hat on the cat or the robot.
So who won the bet?
Our conclusion: we believe the bet should remain on!
To be clear, we’re AI optimists, and I do believe that future models will soon get these 5 prompts right. So if Scott wants to resume the bet, we’re happy to up the ante. (Gary, want to take the other side?)
In the meantime, if you enjoyed this post, check out our other articles on AI prizes, spicy intelligence debates, and human-AI collaboration.






